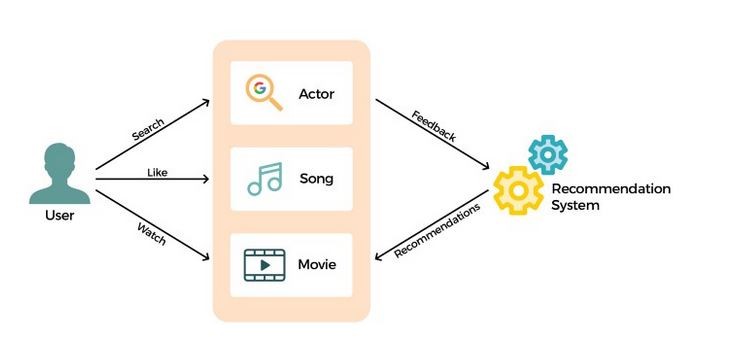
Recommender System Architecture refers to the structured design, workflow, and algorithms behind systems that automatically predict user preferences and suggest the most relevant items—such as movies, products, songs, courses, or news. These systems have become the backbone of digital platforms like Netflix, Amazon, YouTube, Instagram, Zomato, and Spotify, where personalized content directly determines user engagement and business success. At its core, a recommender system attempts to model the relationship between users and items using historical interactions, behavioral patterns, contextual factors, and sometimes explicit feedback such as ratings or likes. The architecture integrates several subsystems: data collection, feature engineering, model training, ranking pipelines, and continuous performance monitoring, all working together to generate real-time recommendations at scale. Designing such systems requires understanding algorithms, data pipelines, distributed computing, evaluation strategies, and business objectives.
A fundamental pillar of recommender system architecture is the data pipeline. Raw data comes from multiple sources—such as user clicks, search queries, browsing histories, purchase transactions, time spent on items, device metadata, and demographic inputs. These data points are collected through event trackers and logs, then stored in scalable data warehouses or lakes. Before feeding into a recommendation model, the data must be cleaned, preprocessed, normalized, and converted into structured formats like user–item interaction matrices or sequential behavior logs. Feature engineering plays a crucial role here, as meaningful features (e.g., recency of interaction, popularity signals, similarity embeddings) improve recommendation quality dramatically. Efficient architectures also support real-time feature updates, allowing systems to adapt instantly to new user actions—like clicking a new video or adding an item to a cart.
At the algorithmic layer, recommender systems typically adopt one of three primary methods: collaborative filtering, content-based filtering, and hybrid models. Collaborative filtering analyzes relationships among users and items based on historical behaviors—identifying users with similar tastes or items frequently consumed together. This technique is effective but suffers when data is sparse or for new users without interaction history (the cold-start problem). Content-based filtering, on the other hand, uses item attributes like genre, price, category, and text descriptions, creating similarity scores that help recommend similar items. This method works well for new items but may limit exploration by recommending only similar content. Hybrid systems solve these limitations by combining the strengths of both approaches, often using weighted algorithms, linear blending, or neural techniques that merge content embeddings with collaborative patterns.
A modern trend in recommender system architecture is the rise of deep learning and representation learning. Neural-based recommenders—such as autoencoders, Recurrent Neural Networks (RNNs), Transformers, and graph neural networks (GNNs)—enable the system to capture complex relationships beyond simple similarity matching. These models generate dense embeddings for users and items, representing them in high-dimensional vector spaces where proximity correlates with relevance. Large-scale companies like YouTube and Amazon use multi-stage deep learning pipelines: candidate generation models retrieve thousands of potential items, while ranking models use more advanced networks to order them precisely. This separation keeps the system efficient, because training a single heavy model to rank millions of items in real time would be computationally infeasible.
Another architectural component is the serving layer, which delivers recommendations to users with minimal latency. Real-time recommender systems depend heavily on fast retrieval infrastructures using approximate nearest neighbor (ANN) search, caching strategies, and distributed model-serving frameworks like TensorFlow Serving or custom microservices. The serving pipeline often consists of multiple stages: (1) candidate retrieval, where the system fetches a manageable subset of items; (2) filtering rules, such as removing already-watched items or applying parental controls; and (3) ranking, where a machine learning model orders the final list according to predicted relevance. Personalization requires computing scores dynamically based on the user’s current context, such as device type, time of day, or recent interactions.
Evaluation and optimization form another crucial block in the architecture. Recommender systems are evaluated using both offline metrics (precision@k, recall@k, NDCG, RMSE) and online metrics measured through A/B testing (CTR, watch time, conversion rate, dwell time). While offline experiments help tune algorithms quickly, real user behavior captured through online tests is far more valuable because it reflects actual preferences and business performance. Some architectures incorporate learning-to-rank frameworks that constantly adjust model parameters based on new data, enabling adaptive and personalized improvements. Exploration vs. exploitation strategies—such as multi-armed bandits—ensure that the system occasionally tries new or less-known items to avoid stagnation and uncover fresh interests.
Scalability and reliability are central to production-grade recommender system design. Large platforms deal with millions of users, billions of interactions, and massive item catalogs. To support this, architectures rely on distributed storage, parallel computation, microservices, sharded databases, and highly optimized search indices. They often employ batch processing for heavy tasks like training and real-time streaming systems like Kafka for incremental updates. Caching layers, message queues, and pre-computed embeddings help ensure the system responds within milliseconds. Disaster recovery, fault tolerance, and failover strategies are equally important to guarantee uninterrupted availability, especially during peak usage times.
A sophisticated architecture also integrates business logic and constraints, ensuring recommendations align with company goals and ethical considerations. For example, e-commerce platforms might promote higher-margin products, while streaming platforms may emphasize diversity of content rather than repeatedly showing the same type of item. Ethical AI guidelines prohibit biased recommendations and require transparency about why a particular item was suggested. Additionally, privacy-preserving techniques such as federated learning or differential privacy are sometimes incorporated to protect sensitive user data while still enabling personalization.
Finally, recommender system architecture is not static—it evolves continuously as user preferences, data distributions, item catalogs, and market conditions change. Modern recommender systems are designed with monitoring dashboards, drift detectors, retraining triggers, and feedback loops that help maintain accuracy over time. Continuous improvement is achieved through iterative experimentation, fine-tuning models, enhancing feature pipelines, adopting new algorithms, and optimizing infrastructure. The ultimate goal is to create a system that feels intuitive, dynamic, and deeply personalized, increasing engagement, satisfaction, and long-term user retention across diverse digital ecosystems.
A fundamental pillar of recommender system architecture is the data pipeline. Raw data comes from multiple sources—such as user clicks, search queries, browsing histories, purchase transactions, time spent on items, device metadata, and demographic inputs. These data points are collected through event trackers and logs, then stored in scalable data warehouses or lakes. Before feeding into a recommendation model, the data must be cleaned, preprocessed, normalized, and converted into structured formats like user–item interaction matrices or sequential behavior logs. Feature engineering plays a crucial role here, as meaningful features (e.g., recency of interaction, popularity signals, similarity embeddings) improve recommendation quality dramatically. Efficient architectures also support real-time feature updates, allowing systems to adapt instantly to new user actions—like clicking a new video or adding an item to a cart.
At the algorithmic layer, recommender systems typically adopt one of three primary methods: collaborative filtering, content-based filtering, and hybrid models. Collaborative filtering analyzes relationships among users and items based on historical behaviors—identifying users with similar tastes or items frequently consumed together. This technique is effective but suffers when data is sparse or for new users without interaction history (the cold-start problem). Content-based filtering, on the other hand, uses item attributes like genre, price, category, and text descriptions, creating similarity scores that help recommend similar items. This method works well for new items but may limit exploration by recommending only similar content. Hybrid systems solve these limitations by combining the strengths of both approaches, often using weighted algorithms, linear blending, or neural techniques that merge content embeddings with collaborative patterns.
A modern trend in recommender system architecture is the rise of deep learning and representation learning. Neural-based recommenders—such as autoencoders, Recurrent Neural Networks (RNNs), Transformers, and graph neural networks (GNNs)—enable the system to capture complex relationships beyond simple similarity matching. These models generate dense embeddings for users and items, representing them in high-dimensional vector spaces where proximity correlates with relevance. Large-scale companies like YouTube and Amazon use multi-stage deep learning pipelines: candidate generation models retrieve thousands of potential items, while ranking models use more advanced networks to order them precisely. This separation keeps the system efficient, because training a single heavy model to rank millions of items in real time would be computationally infeasible.
Another architectural component is the serving layer, which delivers recommendations to users with minimal latency. Real-time recommender systems depend heavily on fast retrieval infrastructures using approximate nearest neighbor (ANN) search, caching strategies, and distributed model-serving frameworks like TensorFlow Serving or custom microservices. The serving pipeline often consists of multiple stages: (1) candidate retrieval, where the system fetches a manageable subset of items; (2) filtering rules, such as removing already-watched items or applying parental controls; and (3) ranking, where a machine learning model orders the final list according to predicted relevance. Personalization requires computing scores dynamically based on the user’s current context, such as device type, time of day, or recent interactions.
Evaluation and optimization form another crucial block in the architecture. Recommender systems are evaluated using both offline metrics (precision@k, recall@k, NDCG, RMSE) and online metrics measured through A/B testing (CTR, watch time, conversion rate, dwell time). While offline experiments help tune algorithms quickly, real user behavior captured through online tests is far more valuable because it reflects actual preferences and business performance. Some architectures incorporate learning-to-rank frameworks that constantly adjust model parameters based on new data, enabling adaptive and personalized improvements. Exploration vs. exploitation strategies—such as multi-armed bandits—ensure that the system occasionally tries new or less-known items to avoid stagnation and uncover fresh interests.
Scalability and reliability are central to production-grade recommender system design. Large platforms deal with millions of users, billions of interactions, and massive item catalogs. To support this, architectures rely on distributed storage, parallel computation, microservices, sharded databases, and highly optimized search indices. They often employ batch processing for heavy tasks like training and real-time streaming systems like Kafka for incremental updates. Caching layers, message queues, and pre-computed embeddings help ensure the system responds within milliseconds. Disaster recovery, fault tolerance, and failover strategies are equally important to guarantee uninterrupted availability, especially during peak usage times.
A sophisticated architecture also integrates business logic and constraints, ensuring recommendations align with company goals and ethical considerations. For example, e-commerce platforms might promote higher-margin products, while streaming platforms may emphasize diversity of content rather than repeatedly showing the same type of item. Ethical AI guidelines prohibit biased recommendations and require transparency about why a particular item was suggested. Additionally, privacy-preserving techniques such as federated learning or differential privacy are sometimes incorporated to protect sensitive user data while still enabling personalization.
Finally, recommender system architecture is not static—it evolves continuously as user preferences, data distributions, item catalogs, and market conditions change. Modern recommender systems are designed with monitoring dashboards, drift detectors, retraining triggers, and feedback loops that help maintain accuracy over time. Continuous improvement is achieved through iterative experimentation, fine-tuning models, enhancing feature pipelines, adopting new algorithms, and optimizing infrastructure. The ultimate goal is to create a system that feels intuitive, dynamic, and deeply personalized, increasing engagement, satisfaction, and long-term user retention across diverse digital ecosystems.