High availability in cloud computing refers to the ability of a system, application, or service to remain accessible and operational for the maximum possible time, even during failures. In the digital world, where users expect applications to work around the clock, downtime can lead to financial losses, reduced productivity, poor customer experience, and reputational damage. Cloud platforms solve this challenge by offering architectures, tools, and built-in mechanisms that ensure services stay alive even when individual components fail. High availability is not just about avoiding downtime; it’s about designing systems that anticipate failures and recover from them automatically without human intervention.
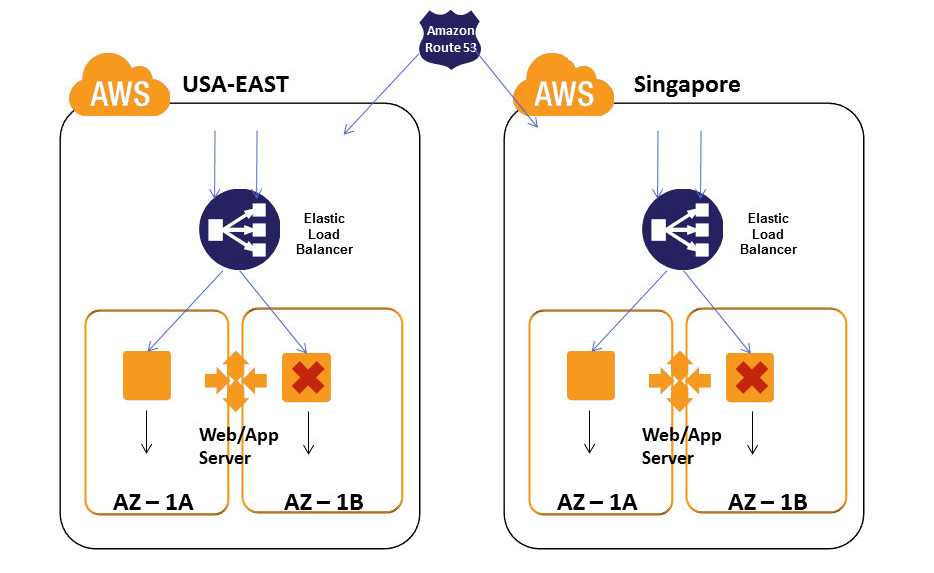
At the core of high availability lies the concept of redundancy. Redundancy means having multiple copies or instances of essential resources so that if one fails, another can take over instantly. In cloud environments, redundancy is implemented across servers, storage systems, network components, and even entire geographical regions. Cloud providers distribute workloads across multiple availability zones—physically separate data centers within a region—to ensure that localized failures do not bring the system down. By spreading resources across these zones, organizations protect themselves from outages caused by hardware failures, power issues, or natural disasters. High availability becomes achievable not through perfect reliability, but through intelligent duplication and smart failover.
Another pillar of high availability is load balancing. Load balancers distribute incoming traffic across multiple instances to prevent any single machine from becoming overloaded. This improves performance while also acting as a layer of fault tolerance. If one instance goes down, the load balancer reroutes traffic to other healthy instances without affecting users. In cloud platforms like AWS, Azure, and Google Cloud, load balancers are highly advanced and integrated with health checks that monitor instance status in real time. When a service becomes unhealthy, the load balancer automatically pulls it out of rotation. This creates a self-healing environment where the system constantly adjusts to maintain availability.
Automatic scaling also plays a critical role in high availability. Applications sometimes crash or slow down not because of failures but due to sudden spikes in user traffic. Auto-scaling mechanisms detect increased load and automatically spin up new instances to handle the demand. When traffic decreases, the extra instances are shut down to save costs. This dynamic scaling ensures that performance remains steady during peak usage while preventing system overload. Cloud-based auto-scaling works seamlessly with load balancers, enabling infrastructure to respond intelligently and adaptively to real-world conditions. It turns predictable and unpredictable traffic patterns into opportunities for resilience rather than risk.
Data redundancy and multi-zone storage are equally essential for high availability. Cloud providers offer storage services that replicate data across availability zones or even across regions. This ensures that data remains accessible even if one storage location fails. Technologies like distributed file systems, erasure coding, snapshot replication, and multi-zone backups provide strong durability and availability guarantees. For applications that rely on databases, cloud providers offer managed database services with built-in failover clusters. These systems continuously replicate data from a primary instance to a standby instance so that failover can happen instantly if the primary node goes down. This level of redundancy ensures that systems do not lose data or become unavailable during failures.
High availability also depends on monitoring and proactive recovery mechanisms. Cloud platforms provide extensive monitoring tools such as AWS CloudWatch, Azure Monitor, and Google Cloud Operations Suite, which track system performance, latency, CPU usage, memory health, and error rates. Monitoring systems trigger alerts and automated responses when they detect anomalies. For example, if an application experiences high response times, the system can automatically scale up resources before performance degradation affects users. Monitoring also enables predictive maintenance by detecting patterns that might lead to failures, allowing organizations to address issues before they escalate. These tools transform raw metrics into actionable insights that strengthen availability.
Failover strategies are another foundational element of high availability. Failover refers to switching service operations from a failing component to a healthy one. In cloud architectures, failover can happen at multiple layers—network, compute, database, storage, or even entire regions. Some applications implement active-passive failover, where a standby instance waits until the primary fails. Others use active-active failover, where multiple instances run simultaneously and share load. Active-active designs ensure greater resilience because the system continues functioning even if one node becomes unavailable. Cloud-native failover mechanisms make these transitions seamless and nearly invisible to users, enabling organizations to operate with minimal disruption.
Designing for high availability requires architectural decisions, not just cloud services. Developers must follow best practices such as removing single points of failure, using stateless application designs, implementing retry logic, performing health checks, adopting distributed systems principles, and designing fault-tolerant workloads. Stateless applications are easier to scale and recover because each instance behaves independently. For stateful components, engineers use distributed caches, replicated databases, and consistent storage systems. By combining cloud-native tools with architectural patterns like microservices, event-driven systems, and container orchestration platforms such as Kubernetes, developers can create applications that remain reliable even in complex environments.
In conclusion, high availability in cloud computing is a comprehensive approach to designing systems that continue to run despite failures. It combines redundancy, load balancing, automatic scaling, data replication, failover mechanisms, monitoring tools, and architectural best practices into a cohesive strategy. Cloud platforms offer the infrastructure and services required to implement high availability at scale, but achieving true resilience also requires thoughtful design and continuous optimization. By embracing high availability principles, organizations can deliver reliable digital experiences, protect critical business operations, and meet the expectations of users who demand uninterrupted access. In the modern cloud-driven landscape, high availability is not optional—it is an essential foundation for building robust, scalable, and future-ready applications.
At the core of high availability lies the concept of redundancy. Redundancy means having multiple copies or instances of essential resources so that if one fails, another can take over instantly. In cloud environments, redundancy is implemented across servers, storage systems, network components, and even entire geographical regions. Cloud providers distribute workloads across multiple availability zones—physically separate data centers within a region—to ensure that localized failures do not bring the system down. By spreading resources across these zones, organizations protect themselves from outages caused by hardware failures, power issues, or natural disasters. High availability becomes achievable not through perfect reliability, but through intelligent duplication and smart failover.
Another pillar of high availability is load balancing. Load balancers distribute incoming traffic across multiple instances to prevent any single machine from becoming overloaded. This improves performance while also acting as a layer of fault tolerance. If one instance goes down, the load balancer reroutes traffic to other healthy instances without affecting users. In cloud platforms like AWS, Azure, and Google Cloud, load balancers are highly advanced and integrated with health checks that monitor instance status in real time. When a service becomes unhealthy, the load balancer automatically pulls it out of rotation. This creates a self-healing environment where the system constantly adjusts to maintain availability.
Automatic scaling also plays a critical role in high availability. Applications sometimes crash or slow down not because of failures but due to sudden spikes in user traffic. Auto-scaling mechanisms detect increased load and automatically spin up new instances to handle the demand. When traffic decreases, the extra instances are shut down to save costs. This dynamic scaling ensures that performance remains steady during peak usage while preventing system overload. Cloud-based auto-scaling works seamlessly with load balancers, enabling infrastructure to respond intelligently and adaptively to real-world conditions. It turns predictable and unpredictable traffic patterns into opportunities for resilience rather than risk.
Data redundancy and multi-zone storage are equally essential for high availability. Cloud providers offer storage services that replicate data across availability zones or even across regions. This ensures that data remains accessible even if one storage location fails. Technologies like distributed file systems, erasure coding, snapshot replication, and multi-zone backups provide strong durability and availability guarantees. For applications that rely on databases, cloud providers offer managed database services with built-in failover clusters. These systems continuously replicate data from a primary instance to a standby instance so that failover can happen instantly if the primary node goes down. This level of redundancy ensures that systems do not lose data or become unavailable during failures.
High availability also depends on monitoring and proactive recovery mechanisms. Cloud platforms provide extensive monitoring tools such as AWS CloudWatch, Azure Monitor, and Google Cloud Operations Suite, which track system performance, latency, CPU usage, memory health, and error rates. Monitoring systems trigger alerts and automated responses when they detect anomalies. For example, if an application experiences high response times, the system can automatically scale up resources before performance degradation affects users. Monitoring also enables predictive maintenance by detecting patterns that might lead to failures, allowing organizations to address issues before they escalate. These tools transform raw metrics into actionable insights that strengthen availability.
Failover strategies are another foundational element of high availability. Failover refers to switching service operations from a failing component to a healthy one. In cloud architectures, failover can happen at multiple layers—network, compute, database, storage, or even entire regions. Some applications implement active-passive failover, where a standby instance waits until the primary fails. Others use active-active failover, where multiple instances run simultaneously and share load. Active-active designs ensure greater resilience because the system continues functioning even if one node becomes unavailable. Cloud-native failover mechanisms make these transitions seamless and nearly invisible to users, enabling organizations to operate with minimal disruption.
Designing for high availability requires architectural decisions, not just cloud services. Developers must follow best practices such as removing single points of failure, using stateless application designs, implementing retry logic, performing health checks, adopting distributed systems principles, and designing fault-tolerant workloads. Stateless applications are easier to scale and recover because each instance behaves independently. For stateful components, engineers use distributed caches, replicated databases, and consistent storage systems. By combining cloud-native tools with architectural patterns like microservices, event-driven systems, and container orchestration platforms such as Kubernetes, developers can create applications that remain reliable even in complex environments.
In conclusion, high availability in cloud computing is a comprehensive approach to designing systems that continue to run despite failures. It combines redundancy, load balancing, automatic scaling, data replication, failover mechanisms, monitoring tools, and architectural best practices into a cohesive strategy. Cloud platforms offer the infrastructure and services required to implement high availability at scale, but achieving true resilience also requires thoughtful design and continuous optimization. By embracing high availability principles, organizations can deliver reliable digital experiences, protect critical business operations, and meet the expectations of users who demand uninterrupted access. In the modern cloud-driven landscape, high availability is not optional—it is an essential foundation for building robust, scalable, and future-ready applications.