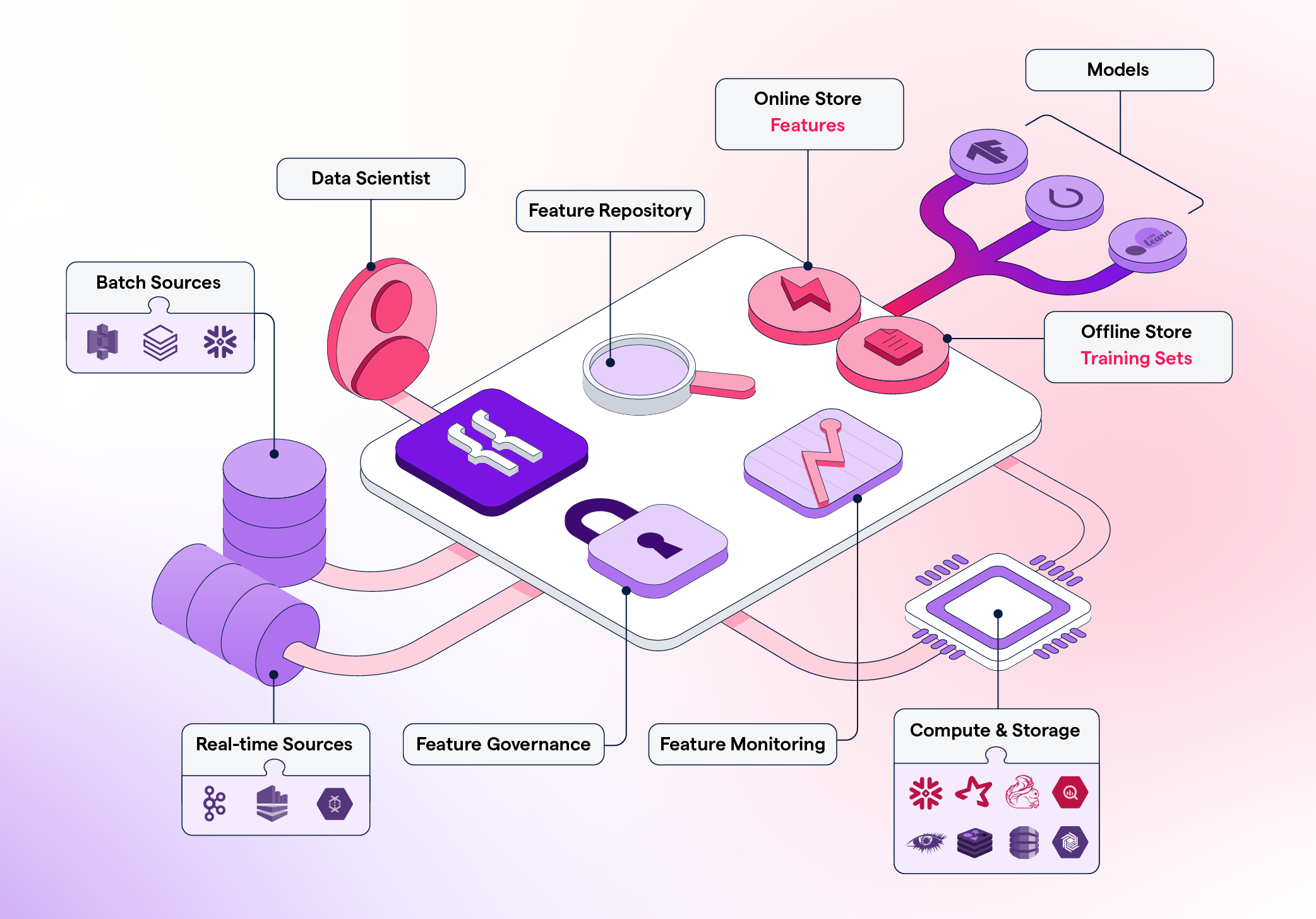
Feature store management has become a core component of modern machine learning infrastructure, enabling organizations to efficiently create, store, share, and reuse features across multiple ML models. In traditional workflows, feature engineering happens independently within different teams, leading to duplication, inconsistencies, and difficulty maintaining feature definitions. A feature store solves this by centralizing the entire lifecycle of feature creation and serving.
A feature store acts as a unified repository that organizes features into well-defined, version-controlled datasets. This structure ensures that every data scientist has access to the same feature definitions, reducing redundancy and eliminating inconsistencies between training and production environments. By maintaining standardized feature schemas, teams can collaborate more efficiently and deploy models with greater confidence.
Operationalizing ML models becomes significantly easier with a feature store. It allows features to be served in two modes: batch mode for training and offline analytics, and real-time mode for low-latency predictions. This dual capability ensures training-serving consistency, one of the biggest challenges in ML pipelines. When the same feature values used in training are also available during inference, models perform more reliably and produce stable predictions.
Feature stores also simplify feature discovery. Data scientists can search, browse, and understand available features without reinventing them for each new project. This speeds up experimentation and avoids unnecessary engineering overhead. By using metadata, lineage tracking, and documentation, feature stores create transparency around how features are generated and updated, improving governance and traceability.
Automation plays a major role in feature store management. Pipelines can automatically compute and refresh features based on data streams, schedules, or triggers. This ensures that features remain up to date and reflect the latest state of the system. Automated validation checks also help ensure that feature values are accurate, consistent, and free from anomalies before being used in model training or production.
Feature stores support scalability as organizations grow. Large enterprises may have hundreds of models that rely on overlapping sets of features. Managing these at scale without centralized infrastructure leads to fragmentation and operational bottlenecks. By unifying feature engineering workflows, a feature store allows teams to build reliable ML systems that maintain consistency across projects and business units.
Security and access control are essential components of feature store management. Sensitive data must be governed carefully, and different roles may require different access permissions. Feature stores help enforce compliance by supporting encryption, audit logs, and fine-grained access policies. This ensures that data governance requirements are met even in highly regulated industries.
Monitoring becomes easier with a feature store. Teams can track feature drift, detect unexpected value changes, and assess whether features remain predictive over time. Real-time monitoring helps organizations detect degradation early, preventing performance issues from affecting downstream models. This contributes to a healthier, more sustainable ML ecosystem.
Feature store management ultimately bridges the gap between data engineering and machine learning operations. By standardizing feature workflows, ensuring consistency across environments, and providing tools for automation and governance, feature stores make ML pipelines more repeatable, scalable, and production-ready. They serve as a critical foundation for enterprise-grade AI systems.
A feature store acts as a unified repository that organizes features into well-defined, version-controlled datasets. This structure ensures that every data scientist has access to the same feature definitions, reducing redundancy and eliminating inconsistencies between training and production environments. By maintaining standardized feature schemas, teams can collaborate more efficiently and deploy models with greater confidence.
Operationalizing ML models becomes significantly easier with a feature store. It allows features to be served in two modes: batch mode for training and offline analytics, and real-time mode for low-latency predictions. This dual capability ensures training-serving consistency, one of the biggest challenges in ML pipelines. When the same feature values used in training are also available during inference, models perform more reliably and produce stable predictions.
Feature stores also simplify feature discovery. Data scientists can search, browse, and understand available features without reinventing them for each new project. This speeds up experimentation and avoids unnecessary engineering overhead. By using metadata, lineage tracking, and documentation, feature stores create transparency around how features are generated and updated, improving governance and traceability.
Automation plays a major role in feature store management. Pipelines can automatically compute and refresh features based on data streams, schedules, or triggers. This ensures that features remain up to date and reflect the latest state of the system. Automated validation checks also help ensure that feature values are accurate, consistent, and free from anomalies before being used in model training or production.
Feature stores support scalability as organizations grow. Large enterprises may have hundreds of models that rely on overlapping sets of features. Managing these at scale without centralized infrastructure leads to fragmentation and operational bottlenecks. By unifying feature engineering workflows, a feature store allows teams to build reliable ML systems that maintain consistency across projects and business units.
Security and access control are essential components of feature store management. Sensitive data must be governed carefully, and different roles may require different access permissions. Feature stores help enforce compliance by supporting encryption, audit logs, and fine-grained access policies. This ensures that data governance requirements are met even in highly regulated industries.
Monitoring becomes easier with a feature store. Teams can track feature drift, detect unexpected value changes, and assess whether features remain predictive over time. Real-time monitoring helps organizations detect degradation early, preventing performance issues from affecting downstream models. This contributes to a healthier, more sustainable ML ecosystem.
Feature store management ultimately bridges the gap between data engineering and machine learning operations. By standardizing feature workflows, ensuring consistency across environments, and providing tools for automation and governance, feature stores make ML pipelines more repeatable, scalable, and production-ready. They serve as a critical foundation for enterprise-grade AI systems.