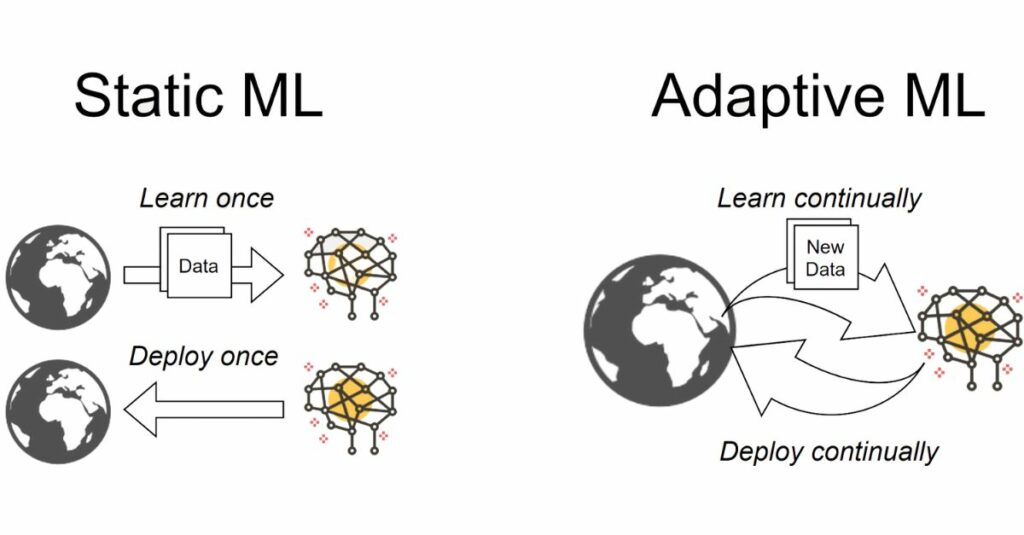
Continual Learning, also known as Lifelong Learning or Incremental Learning, is a machine learning approach where an AI model learns continuously over time by acquiring new knowledge while preserving previously learned information. Unlike traditional ML models that are trained once on a fixed dataset, continual learning systems keep updating themselves as new data arrives, making them more adaptable and intelligent in real-world environments.
In real-world applications, data keeps changing—for example, new types of cyberattacks, evolving user behavior in apps, or changing road conditions for self-driving cars. Continual learning allows AI models to adjust to these changes without needing full retraining from scratch. This reduces computational cost and enables real-time adaptation, making AI systems more efficient and scalable.
A major challenge in continual learning is catastrophic forgetting, where the model forgets old knowledge when trained on new data. To overcome this, continual learning uses techniques like regularization-based methods (e.g., Elastic Weight Consolidation), replay-based methods (using memory buffers or generative replay), and architecture-based methods (expanding networks or dynamic layers). These ensure the model preserves past knowledge while integrating new information.
Continual learning can be applied in three main scenarios: Task-incremental learning, where the model learns different tasks sequentially; Domain-incremental learning, where the environment changes but the task remains the same; and Class-incremental learning, where new classes are added over time. These variations help build flexible systems that handle evolving datasets and conditions.
Continual learning is crucial for robotics, personalized AI assistants, recommender systems, healthcare monitoring, fraud detection, autonomous vehicles, and cybersecurity. These areas require constant adaptation because the environment or user behavior changes over time. By learning dynamically, systems become more intelligent and consistent with human-like learning patterns.
Advantages
1)More adaptive and flexible models
2)Efficient use of computational resources
3)Better performance in real-world scenarios
4)Handles evolving data and tasks
Disadvantages
1)Difficult to prevent forgetting completely
2)Requires complex training strategies
3)Memory and storage management challenges
4)Performance can drop if data sequence is imbalanced
In real-world applications, data keeps changing—for example, new types of cyberattacks, evolving user behavior in apps, or changing road conditions for self-driving cars. Continual learning allows AI models to adjust to these changes without needing full retraining from scratch. This reduces computational cost and enables real-time adaptation, making AI systems more efficient and scalable.
A major challenge in continual learning is catastrophic forgetting, where the model forgets old knowledge when trained on new data. To overcome this, continual learning uses techniques like regularization-based methods (e.g., Elastic Weight Consolidation), replay-based methods (using memory buffers or generative replay), and architecture-based methods (expanding networks or dynamic layers). These ensure the model preserves past knowledge while integrating new information.
Continual learning can be applied in three main scenarios: Task-incremental learning, where the model learns different tasks sequentially; Domain-incremental learning, where the environment changes but the task remains the same; and Class-incremental learning, where new classes are added over time. These variations help build flexible systems that handle evolving datasets and conditions.
Continual learning is crucial for robotics, personalized AI assistants, recommender systems, healthcare monitoring, fraud detection, autonomous vehicles, and cybersecurity. These areas require constant adaptation because the environment or user behavior changes over time. By learning dynamically, systems become more intelligent and consistent with human-like learning patterns.
Advantages
1)More adaptive and flexible models
2)Efficient use of computational resources
3)Better performance in real-world scenarios
4)Handles evolving data and tasks
Disadvantages
1)Difficult to prevent forgetting completely
2)Requires complex training strategies
3)Memory and storage management challenges
4)Performance can drop if data sequence is imbalanced