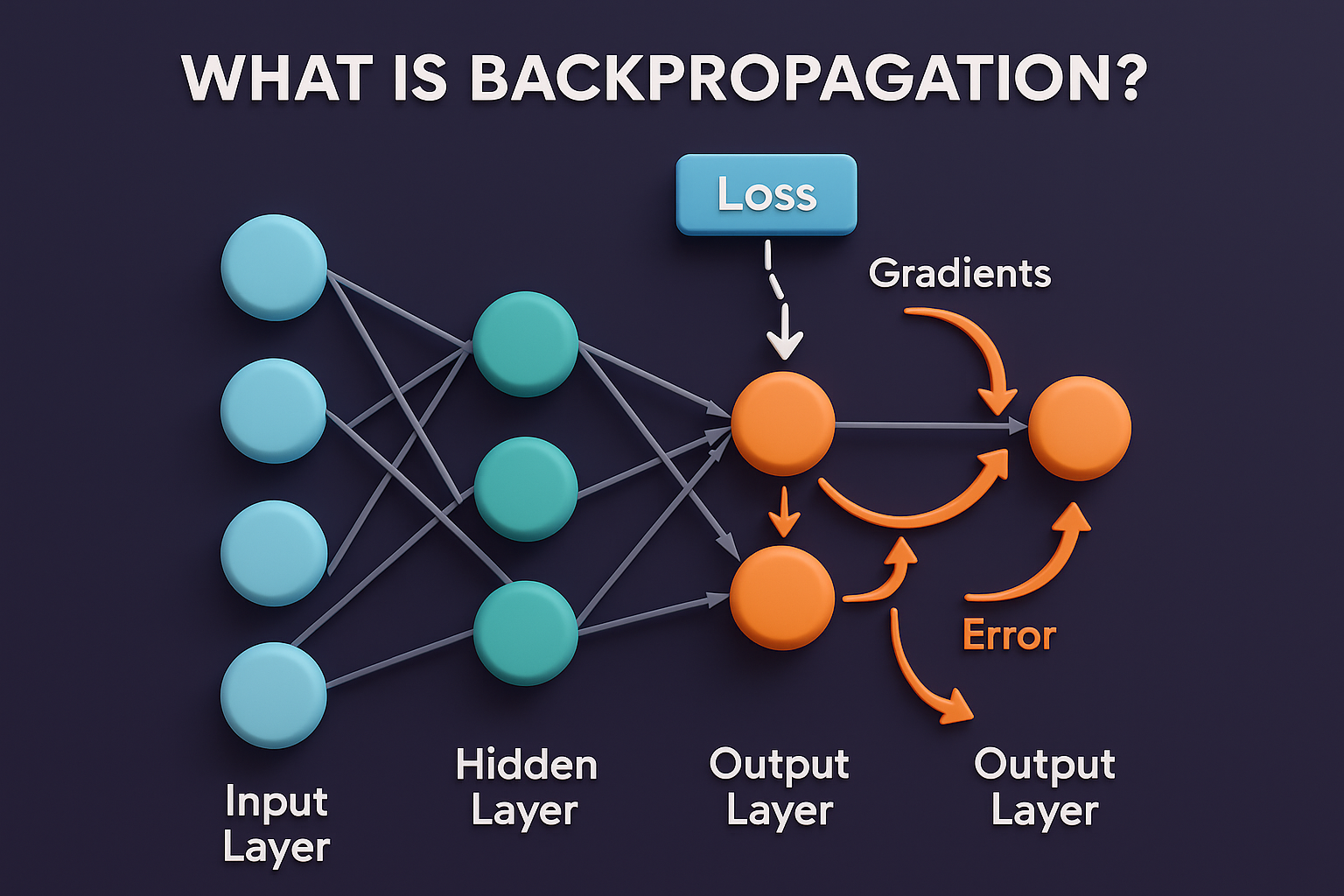
Backpropagation is the core algorithm that allows neural networks to learn from data by adjusting their internal parameters through repeated training cycles. It is the process through which a neural network reduces its errors by comparing predicted outputs with actual values and updating its weights accordingly. Without backpropagation, deep learning as we know it would not be possible. The algorithm powers everything from image recognition and speech processing to recommendation systems and large language models. It is the mathematical engine behind a neural network’s ability to improve performance over time.
Neural networks consist of multiple layers of neurons, each performing mathematical operations to transform inputs into outputs. During the forward pass, data flows from the input layer through hidden layers to the output layer, generating a prediction. This prediction is compared to the correct output using a loss function, which measures how wrong the model is. Backpropagation begins when the network uses this loss value to calculate how much each weight contributed to the error. This calculation is based on the chain rule of calculus, which makes it possible to compute gradients layer by layer.
The central idea of backpropagation is gradient computation. Gradients tell the model how sensitive the loss is to each individual weight. If a weight contributes heavily to the error, it receives a larger gradient, meaning it needs a significant update. If its influence is small, the gradient will also be small. By calculating these gradients for all weights in the network, backpropagation determines the exact direction in which each weight should change. This step transforms a neural network from a static system into an adaptive learning machine capable of refining itself with every iteration.
Once gradients are computed, the next step is weight updating, which is performed using an optimization algorithm. The most commonly used optimizer is Gradient Descent, along with its variants such as Adam, RMSProp, and SGD with momentum. These optimizers use gradients to modify weights in a way that reduces the overall loss. The learning rate controls how big or small these weight updates are. If the learning rate is too high, the model may overshoot optimal values. If it’s too low, training becomes slow. The interaction of backpropagation and optimization creates an efficient learning loop.
Backpropagation relies heavily on the chain rule of calculus to propagate errors from the output layer backward through the network. The chain rule enables the algorithm to break complex derivative calculations into smaller, manageable pieces. By applying the chain rule, backprop can determine how much each neuron contributed to the final error. This backward flow of information is why the algorithm is called “back-propagation”—it propagates errors backward from output to input. As a result, deeper layers learn more abstract features, such as shapes, patterns, or linguistic relationships, depending on the application.
Activation functions also play an important role in backpropagation. Functions like ReLU, Sigmoid, and Tanh introduce non-linearity, allowing networks to learn complex patterns. However, they also affect the flow of gradients. For example, the Sigmoid function compresses values into the range of 0 to 1, which can cause gradients to vanish during backpropagation—making it difficult for deep networks to learn. This issue, known as the vanishing gradient problem, led to the development of better activation functions like ReLU, which maintain stronger gradients and improve learning in deeper networks.
Backpropagation is not only used in training but also influences how deep learning architectures are designed. Convolutional neural networks for vision, recurrent networks for sequence prediction, and transformers for language all rely on backpropagation at their core. Researchers and engineers modify architecture depth, layer types, and connectivity patterns to ensure gradients flow smoothly during backpropagation. Skip connections in ResNet, for example, were designed specifically to solve gradient flow problems. These innovations demonstrate how deeply backpropagation is intertwined with neural network evolution.
Despite its power, backpropagation requires large amounts of labeled data, computational resources, and careful tuning to work effectively. Training deep models often demands GPUs, large datasets, and multiple iterations. Researchers are exploring alternatives and improvements such as self-supervised learning, reinforcement learning, and biologically inspired algorithms. However, backpropagation remains the dominant method because of its mathematical efficiency and proven success across industries. It continues to form the foundation of nearly all major breakthroughs in AI, making it one of the most important concepts in machine learning.
Overall, backpropagation is the learning engine of neural networks, enabling them to adjust weights, minimize errors, and improve performance over time. It connects prediction, error evaluation, gradient calculation, and optimization into a seamless process that powers modern deep learning. Understanding backpropagation is essential for anyone studying AI or machine learning because it explains how machines transform raw data into intelligent decision-making capabilities. It stands as one of the most influential algorithms in modern technology, driving advancements in vision, speech, language, robotics, and countless other domains.
Neural networks consist of multiple layers of neurons, each performing mathematical operations to transform inputs into outputs. During the forward pass, data flows from the input layer through hidden layers to the output layer, generating a prediction. This prediction is compared to the correct output using a loss function, which measures how wrong the model is. Backpropagation begins when the network uses this loss value to calculate how much each weight contributed to the error. This calculation is based on the chain rule of calculus, which makes it possible to compute gradients layer by layer.
The central idea of backpropagation is gradient computation. Gradients tell the model how sensitive the loss is to each individual weight. If a weight contributes heavily to the error, it receives a larger gradient, meaning it needs a significant update. If its influence is small, the gradient will also be small. By calculating these gradients for all weights in the network, backpropagation determines the exact direction in which each weight should change. This step transforms a neural network from a static system into an adaptive learning machine capable of refining itself with every iteration.
Once gradients are computed, the next step is weight updating, which is performed using an optimization algorithm. The most commonly used optimizer is Gradient Descent, along with its variants such as Adam, RMSProp, and SGD with momentum. These optimizers use gradients to modify weights in a way that reduces the overall loss. The learning rate controls how big or small these weight updates are. If the learning rate is too high, the model may overshoot optimal values. If it’s too low, training becomes slow. The interaction of backpropagation and optimization creates an efficient learning loop.
Backpropagation relies heavily on the chain rule of calculus to propagate errors from the output layer backward through the network. The chain rule enables the algorithm to break complex derivative calculations into smaller, manageable pieces. By applying the chain rule, backprop can determine how much each neuron contributed to the final error. This backward flow of information is why the algorithm is called “back-propagation”—it propagates errors backward from output to input. As a result, deeper layers learn more abstract features, such as shapes, patterns, or linguistic relationships, depending on the application.
Activation functions also play an important role in backpropagation. Functions like ReLU, Sigmoid, and Tanh introduce non-linearity, allowing networks to learn complex patterns. However, they also affect the flow of gradients. For example, the Sigmoid function compresses values into the range of 0 to 1, which can cause gradients to vanish during backpropagation—making it difficult for deep networks to learn. This issue, known as the vanishing gradient problem, led to the development of better activation functions like ReLU, which maintain stronger gradients and improve learning in deeper networks.
Backpropagation is not only used in training but also influences how deep learning architectures are designed. Convolutional neural networks for vision, recurrent networks for sequence prediction, and transformers for language all rely on backpropagation at their core. Researchers and engineers modify architecture depth, layer types, and connectivity patterns to ensure gradients flow smoothly during backpropagation. Skip connections in ResNet, for example, were designed specifically to solve gradient flow problems. These innovations demonstrate how deeply backpropagation is intertwined with neural network evolution.
Despite its power, backpropagation requires large amounts of labeled data, computational resources, and careful tuning to work effectively. Training deep models often demands GPUs, large datasets, and multiple iterations. Researchers are exploring alternatives and improvements such as self-supervised learning, reinforcement learning, and biologically inspired algorithms. However, backpropagation remains the dominant method because of its mathematical efficiency and proven success across industries. It continues to form the foundation of nearly all major breakthroughs in AI, making it one of the most important concepts in machine learning.
Overall, backpropagation is the learning engine of neural networks, enabling them to adjust weights, minimize errors, and improve performance over time. It connects prediction, error evaluation, gradient calculation, and optimization into a seamless process that powers modern deep learning. Understanding backpropagation is essential for anyone studying AI or machine learning because it explains how machines transform raw data into intelligent decision-making capabilities. It stands as one of the most influential algorithms in modern technology, driving advancements in vision, speech, language, robotics, and countless other domains.