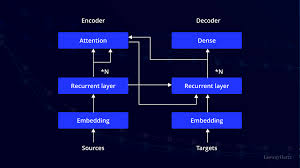
Transformers are a modern deep learning architecture that fundamentally transformed the way sequential data is modeled by removing the need for recurrence and convolution. Instead of processing data step by step, transformers rely entirely on attention mechanisms to understand relationships within a sequence. This shift in design has made transformers one of the most influential and widely adopted architectures in artificial intelligence.
The core innovation behind transformers is the self-attention mechanism. Self-attention allows the model to examine all elements in a sequence at the same time and determine how strongly each element is related to every other element. By assigning attention weights, the model learns which parts of the input are most relevant when generating representations, enabling a richer understanding of context and meaning.
Unlike recurrent neural networks, which process sequences sequentially, transformers enable parallel processing of input data. This parallelism significantly improves training speed and scalability, especially on large datasets. Because all sequence elements are processed simultaneously, transformers are well suited for modern hardware such as GPUs and TPUs, making them more efficient than traditional sequence models.
Transformers have achieved exceptional success in natural language processing tasks. They are widely used for machine translation, text summarization, question answering, sentiment analysis, and text generation. Their ability to capture contextual relationships across entire sequences allows them to produce more accurate and coherent language representations compared to earlier models.
A major breakthrough in transformer adoption came with the introduction of large pre-trained models such as BERT, GPT, and T5. These models are trained on massive text corpora and then fine-tuned for specific tasks. Pre-training enables them to learn general language patterns, resulting in state-of-the-art performance across a wide range of applications with relatively small amounts of task-specific data.
Transformers are particularly effective at modeling long-range dependencies within sequences. While RNN-based models struggle to retain information over long distances, transformers use self-attention to directly connect distant elements in a sequence. This allows them to capture global context without the bottlenecks of sequential processing.
Despite their strengths, transformers come with challenges, especially in terms of computational cost. Training large transformer models requires significant memory, processing power, and large-scale datasets. As a result, optimization techniques such as model compression, sparse attention, and efficient architectures are active areas of research aimed at reducing resource requirements.
Beyond natural language processing, transformers have expanded into other domains such as computer vision, speech recognition, and multimodal AI systems. Vision Transformers, audio transformers, and models that combine text, image, and audio inputs demonstrate the versatility of this architecture. Overall, transformers have become a foundational technology in modern AI, driving innovation across multiple fields.
The core innovation behind transformers is the self-attention mechanism. Self-attention allows the model to examine all elements in a sequence at the same time and determine how strongly each element is related to every other element. By assigning attention weights, the model learns which parts of the input are most relevant when generating representations, enabling a richer understanding of context and meaning.
Unlike recurrent neural networks, which process sequences sequentially, transformers enable parallel processing of input data. This parallelism significantly improves training speed and scalability, especially on large datasets. Because all sequence elements are processed simultaneously, transformers are well suited for modern hardware such as GPUs and TPUs, making them more efficient than traditional sequence models.
Transformers have achieved exceptional success in natural language processing tasks. They are widely used for machine translation, text summarization, question answering, sentiment analysis, and text generation. Their ability to capture contextual relationships across entire sequences allows them to produce more accurate and coherent language representations compared to earlier models.
A major breakthrough in transformer adoption came with the introduction of large pre-trained models such as BERT, GPT, and T5. These models are trained on massive text corpora and then fine-tuned for specific tasks. Pre-training enables them to learn general language patterns, resulting in state-of-the-art performance across a wide range of applications with relatively small amounts of task-specific data.
Transformers are particularly effective at modeling long-range dependencies within sequences. While RNN-based models struggle to retain information over long distances, transformers use self-attention to directly connect distant elements in a sequence. This allows them to capture global context without the bottlenecks of sequential processing.
Despite their strengths, transformers come with challenges, especially in terms of computational cost. Training large transformer models requires significant memory, processing power, and large-scale datasets. As a result, optimization techniques such as model compression, sparse attention, and efficient architectures are active areas of research aimed at reducing resource requirements.
Beyond natural language processing, transformers have expanded into other domains such as computer vision, speech recognition, and multimodal AI systems. Vision Transformers, audio transformers, and models that combine text, image, and audio inputs demonstrate the versatility of this architecture. Overall, transformers have become a foundational technology in modern AI, driving innovation across multiple fields.