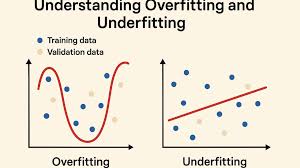
In Machine Learning, building a model that performs well on both training data and unseen data is the ultimate goal. However, this is not always easy, and two of the most common issues that prevent a model from performing effectively are overfitting and underfitting. These problems are fundamental to understanding how models learn patterns from data. Overfitting happens when a model learns too much from the training data—including noise and irrelevant details—leading to poor performance on new data. Underfitting occurs when the model fails to capture the underlying patterns and performs poorly on both training and test datasets. Mastering these concepts is crucial because the ability to control model fit determines the success of any predictive system. A well-balanced model should generalize well, meaning it performs consistently across all datasets.
Overfitting occurs when a model becomes excessively complex and starts memorizing the training data instead of learning general patterns. This typically happens when the model has too many parameters or is trained for too long. In overfitting, the model fits the training data so closely that even random noise is treated as meaningful information. As a result, training accuracy becomes extremely high, but test accuracy drops significantly. Imagine a student who memorizes every example in a textbook without understanding the concepts. They perform perfectly on the examples they studied but struggle with new questions. This is the exact behavior of an overfitted model. It appears confident but fails to generalize, making it unreliable for real-world predictions.
Underfitting is the opposite problem. It happens when the model is too simple to capture the hidden patterns in the data. A classic example is using a straight line to fit data that actually follows a curve. In such cases, the model’s predictions will be inaccurate both on training data and on test data. Underfitting often occurs when the model lacks sufficient parameters, features are inadequate, or training is not long enough. It is similar to a student who barely studies and knows only the basics—they perform poorly regardless of the difficulty of questions. Underfitted models are easy to spot because they consistently produce high error rates and exhibit low accuracy everywhere.
To understand overfitting and underfitting deeply, one must learn the bias-variance trade-off, a core machine learning concept. High bias occurs when a model makes strong assumptions, leading to underfitting. High variance occurs when the model becomes too sensitive to small fluctuations in the training data, leading to overfitting. A good model strikes a balance where both bias and variance are kept low. The key idea is to build a model that is neither too simple nor excessively complex. Techniques such as increasing data, simplifying model architecture, adding regularization, or tuning hyperparameters help achieve this balance. The bias-variance trade-off is the foundation of model optimization and is essential for achieving strong generalization performance.
Overfitting is commonly caused by complex models, insufficient training data, noisy datasets, or long training periods. Algorithms like deep neural networks are prone to overfitting when not properly regularized. Underfitting, meanwhile, is caused by overly simple models, insufficient training, low-quality features, or excessive regularization. Understanding these causes helps developers diagnose problems effectively. For example, using a small decision tree may lead to underfitting, while using a deep neural network without dropout may lead to overfitting. Both problems stem from incorrect model configuration and poor dataset understanding. The key is choosing the right level of model complexity based on the nature of the problem and the size of the dataset.
There are clear indicators for identifying overfitting. If your training accuracy is extremely high but test accuracy is low, the model is overfitting. Large gaps between training and validation errors also confirm this. Underfitting can be detected when both training and validation performance are poor, indicating that the model is not learning adequately. Visualization tools such as learning curves play a major role in identifying these issues. Learning curves help monitor model behavior over training epochs, making it easier to see whether the model is approaching generalization or drifting into overfitting. Detecting these problems early allows engineers to adjust model parameters before final deployment.
Overfitting can be reduced through several powerful techniques. Regularization methods such as L1, L2, or ElasticNet add penalties to large model weights, discouraging complexity. Dropout randomly disables neurons during training, preventing the model from relying too heavily on specific features. Early stopping monitors validation error and halts training before overfitting begins. Increasing the size of the training dataset or applying data augmentation also helps by exposing the model to more varied examples. Another effective approach is to reduce model complexity, such as using smaller networks or pruning decision trees. These methods collectively help create more generalized models that perform well in real-world environments.
Solving underfitting requires increasing model capacity or improving feature richness. Adding more layers or neurons to a neural network, increasing tree depth in decision trees, or using more advanced algorithms often reduces underfitting. Extending training duration helps the model learn deeper patterns. Feature engineering is another powerful solution—adding meaningful variables, transforming existing features, or removing irrelevant ones can dramatically improve model performance. Reducing regularization strength is also effective when the model is overly constrained. In many cases, underfitting is resolved simply by choosing a more suitable algorithm for the data type and complexity.
Overfitting and underfitting are two of the most important challenges in Machine Learning, directly impacting model performance and reliability. Understanding their causes, symptoms, and solutions allows practitioners to build models that generalize well and perform consistently across various datasets. By mastering techniques such as regularization, proper model selection, balanced training, and feature engineering, developers can achieve optimal model performance. A strong grasp of these concepts empowers beginners and professionals alike to create AI systems that are accurate, robust, and production-ready. Good machine learning is not just about high accuracy—it is about building models that understand real patterns and behave reliably in the real world.
Overfitting occurs when a model becomes excessively complex and starts memorizing the training data instead of learning general patterns. This typically happens when the model has too many parameters or is trained for too long. In overfitting, the model fits the training data so closely that even random noise is treated as meaningful information. As a result, training accuracy becomes extremely high, but test accuracy drops significantly. Imagine a student who memorizes every example in a textbook without understanding the concepts. They perform perfectly on the examples they studied but struggle with new questions. This is the exact behavior of an overfitted model. It appears confident but fails to generalize, making it unreliable for real-world predictions.
Underfitting is the opposite problem. It happens when the model is too simple to capture the hidden patterns in the data. A classic example is using a straight line to fit data that actually follows a curve. In such cases, the model’s predictions will be inaccurate both on training data and on test data. Underfitting often occurs when the model lacks sufficient parameters, features are inadequate, or training is not long enough. It is similar to a student who barely studies and knows only the basics—they perform poorly regardless of the difficulty of questions. Underfitted models are easy to spot because they consistently produce high error rates and exhibit low accuracy everywhere.
To understand overfitting and underfitting deeply, one must learn the bias-variance trade-off, a core machine learning concept. High bias occurs when a model makes strong assumptions, leading to underfitting. High variance occurs when the model becomes too sensitive to small fluctuations in the training data, leading to overfitting. A good model strikes a balance where both bias and variance are kept low. The key idea is to build a model that is neither too simple nor excessively complex. Techniques such as increasing data, simplifying model architecture, adding regularization, or tuning hyperparameters help achieve this balance. The bias-variance trade-off is the foundation of model optimization and is essential for achieving strong generalization performance.
Overfitting is commonly caused by complex models, insufficient training data, noisy datasets, or long training periods. Algorithms like deep neural networks are prone to overfitting when not properly regularized. Underfitting, meanwhile, is caused by overly simple models, insufficient training, low-quality features, or excessive regularization. Understanding these causes helps developers diagnose problems effectively. For example, using a small decision tree may lead to underfitting, while using a deep neural network without dropout may lead to overfitting. Both problems stem from incorrect model configuration and poor dataset understanding. The key is choosing the right level of model complexity based on the nature of the problem and the size of the dataset.
There are clear indicators for identifying overfitting. If your training accuracy is extremely high but test accuracy is low, the model is overfitting. Large gaps between training and validation errors also confirm this. Underfitting can be detected when both training and validation performance are poor, indicating that the model is not learning adequately. Visualization tools such as learning curves play a major role in identifying these issues. Learning curves help monitor model behavior over training epochs, making it easier to see whether the model is approaching generalization or drifting into overfitting. Detecting these problems early allows engineers to adjust model parameters before final deployment.
Overfitting can be reduced through several powerful techniques. Regularization methods such as L1, L2, or ElasticNet add penalties to large model weights, discouraging complexity. Dropout randomly disables neurons during training, preventing the model from relying too heavily on specific features. Early stopping monitors validation error and halts training before overfitting begins. Increasing the size of the training dataset or applying data augmentation also helps by exposing the model to more varied examples. Another effective approach is to reduce model complexity, such as using smaller networks or pruning decision trees. These methods collectively help create more generalized models that perform well in real-world environments.
Solving underfitting requires increasing model capacity or improving feature richness. Adding more layers or neurons to a neural network, increasing tree depth in decision trees, or using more advanced algorithms often reduces underfitting. Extending training duration helps the model learn deeper patterns. Feature engineering is another powerful solution—adding meaningful variables, transforming existing features, or removing irrelevant ones can dramatically improve model performance. Reducing regularization strength is also effective when the model is overly constrained. In many cases, underfitting is resolved simply by choosing a more suitable algorithm for the data type and complexity.
Overfitting and underfitting are two of the most important challenges in Machine Learning, directly impacting model performance and reliability. Understanding their causes, symptoms, and solutions allows practitioners to build models that generalize well and perform consistently across various datasets. By mastering techniques such as regularization, proper model selection, balanced training, and feature engineering, developers can achieve optimal model performance. A strong grasp of these concepts empowers beginners and professionals alike to create AI systems that are accurate, robust, and production-ready. Good machine learning is not just about high accuracy—it is about building models that understand real patterns and behave reliably in the real world.