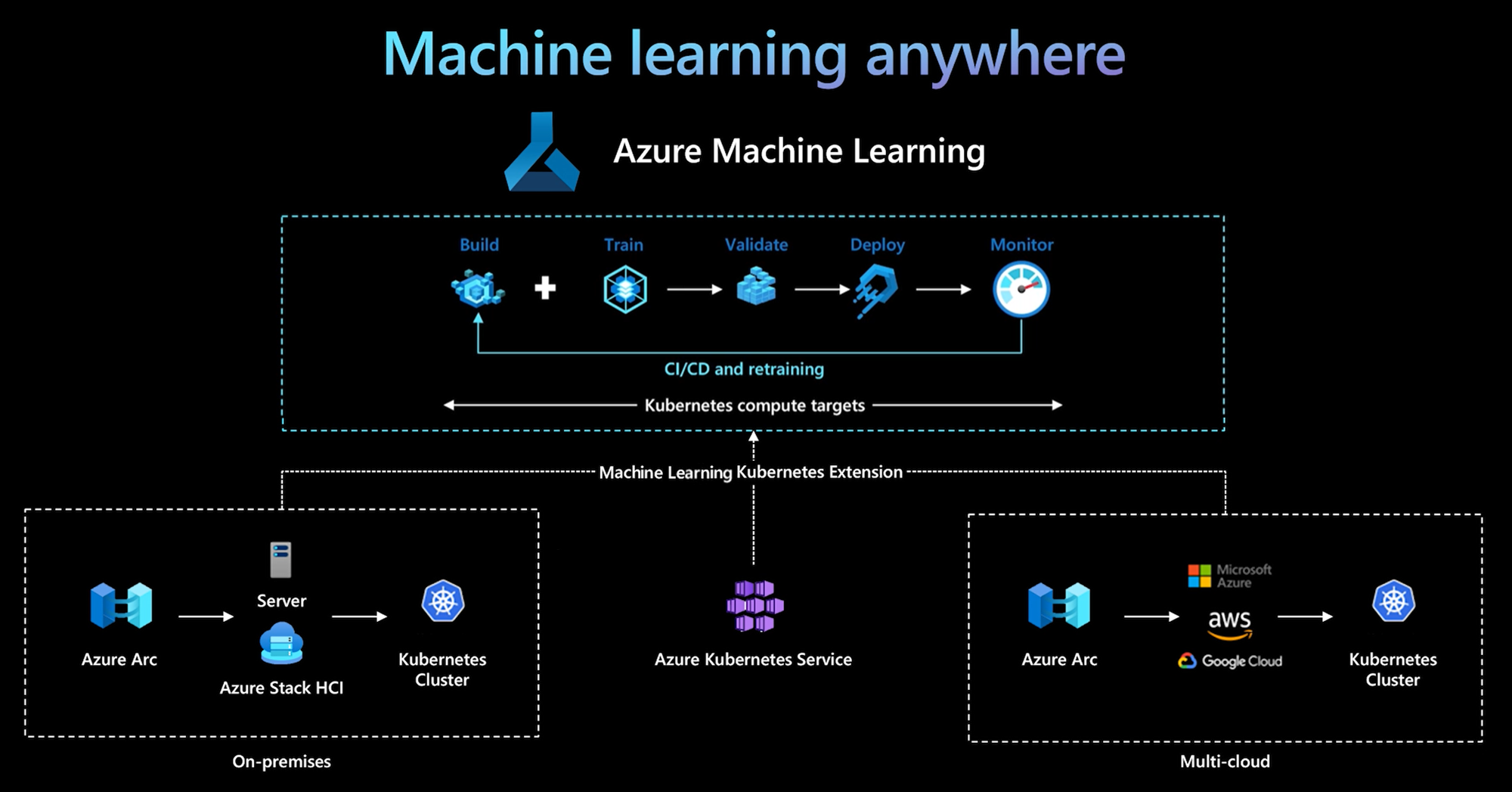
Model Deployment and MLOps are critical components in the machine learning lifecycle, ensuring that models developed in experimentation stages are successfully delivered into real-world environments. While building a machine learning model in a notebook is relatively straightforward, deploying it into production at scale requires infrastructure, automation, monitoring, and collaboration across data science, DevOps, and engineering teams. MLOps (Machine Learning Operations) extends DevOps principles to the ML workflow, enabling continuous integration, continuous delivery, and continuous training of models. Together, model deployment and MLOps bridge the gap between experimentation and impact, ensuring that machine learning outputs bring real value to users and businesses.
Model deployment begins once a model is trained, evaluated, and selected as the best candidate. Deployment means making that model available for real-time or batch predictions. In real-time (online) deployment, the model typically runs behind an API endpoint using frameworks like Flask, FastAPI, or TensorFlow Serving. When an application sends data, the model returns predictions instantly. Batch deployment, on the other hand, involves processing large volumes of data at scheduled intervals, such as generating daily product recommendations or fraud alerts. Deployment strategy depends on use case requirements: latency-critical applications need fast responses, while analytics-heavy tasks use batch processing for scalability.
One of the biggest challenges with deployment is the difference between development and production environments. In development, the data scientist trains the model with specific libraries, versions, and data samples. In production, the environment may be different, and the model may behave inconsistently. Containerization technologies like Docker solve this problem by packaging the model along with its dependencies so it behaves the same everywhere. Tools like Kubernetes orchestrate these containers at scale, ensuring high availability, automated scaling, and fault tolerance. This allows models to handle millions of requests smoothly without downtime.
MLOps frameworks introduce automation to the entire lifecycle—data collection, preprocessing, training, validation, deployment, monitoring, and retraining. Continuous Integration (CI) tests data pipelines, model code, and feature transformations. Continuous Delivery (CD) automates deployment to staging or production environments. Continuous Training (CT) ensures that models can be retrained periodically or dynamically when new data arrives. Tools like MLflow, Kubeflow, Airflow, and Vertex AI allow teams to build workflows, track experiment results, manage models, and version datasets. This automation reduces manual work, improves reliability, and accelerates ML development cycles.
Monitoring is one of the most important—and often overlooked—parts of MLOps. Once deployed, models must be monitored for performance, latency, system health, and accuracy drift. Data in production changes constantly, sometimes gradually (known as data drift) or suddenly (known as concept drift). A model that works well today may become inaccurate tomorrow if user behavior shifts, new competitors enter the market, or external factors such as economic changes or seasonality arise. Monitoring tools track prediction distributions, feature fluctuations, error rates, and confidence levels. Alerts notify teams when retraining or recalibration becomes necessary.
Retraining and updating models are essential for keeping performance optimal. In offline retraining, new data is collected periodically and used to retrain the model at scheduled intervals. Online learning or incremental training updates the model continuously as new data comes in. Automation pipelines manage versioning to ensure older and newer models can be compared and rolled back if needed. Model registries like MLflow Model Registry or Amazon SageMaker Registry track multiple versions, metadata, validation metrics, and deployment history. These registries serve as a central hub for approving, promoting, or retiring models.
Security and governance play a major role in MLOps, especially in industries like healthcare, banking, and cybersecurity. Models can unintentionally expose sensitive data or behave unpredictably under adversarial attacks. Secure MLOps practices include encrypted endpoints, API authentication, role-based access control, audit trails, and ensuring training data complies with regulations like GDPR or HIPAA. Bias detection is also part of ethical MLOps—monitoring model predictions to ensure fairness across demographic groups and preventing discriminatory outcomes. Governance frameworks ensure the model remains compliant, safe, and transparent during its entire lifecycle.
Scaling MLOps requires collaboration across multiple teams, not just data scientists. Engineers, DevOps specialists, cloud architects, and product managers all contribute to building a robust ML ecosystem. Cloud platforms such as AWS, Azure, and Google Cloud offer managed MLOps solutions like SageMaker, AzureML, and Vertex AI, reducing complexity and making deployment more accessible. These platforms integrate storage, compute, model training, monitoring, and pipelines in a unified ecosystem. As machine learning applications expand further into personalization, automation, prediction, and optimization, organizations with strong MLOps practices gain a competitive advantage.
Model Deployment and MLOps transform machine learning from a research activity into a scalable production system capable of delivering business value continuously. They empower companies to adapt quickly to new data, maintain accuracy in changing environments, and confidently rely on AI to support critical decisions. As ML adoption grows worldwide, MLOps is rapidly becoming a must-have discipline—ensuring stability, reliability, automation, and long-term performance of machine learning systems.
Model deployment begins once a model is trained, evaluated, and selected as the best candidate. Deployment means making that model available for real-time or batch predictions. In real-time (online) deployment, the model typically runs behind an API endpoint using frameworks like Flask, FastAPI, or TensorFlow Serving. When an application sends data, the model returns predictions instantly. Batch deployment, on the other hand, involves processing large volumes of data at scheduled intervals, such as generating daily product recommendations or fraud alerts. Deployment strategy depends on use case requirements: latency-critical applications need fast responses, while analytics-heavy tasks use batch processing for scalability.
One of the biggest challenges with deployment is the difference between development and production environments. In development, the data scientist trains the model with specific libraries, versions, and data samples. In production, the environment may be different, and the model may behave inconsistently. Containerization technologies like Docker solve this problem by packaging the model along with its dependencies so it behaves the same everywhere. Tools like Kubernetes orchestrate these containers at scale, ensuring high availability, automated scaling, and fault tolerance. This allows models to handle millions of requests smoothly without downtime.
MLOps frameworks introduce automation to the entire lifecycle—data collection, preprocessing, training, validation, deployment, monitoring, and retraining. Continuous Integration (CI) tests data pipelines, model code, and feature transformations. Continuous Delivery (CD) automates deployment to staging or production environments. Continuous Training (CT) ensures that models can be retrained periodically or dynamically when new data arrives. Tools like MLflow, Kubeflow, Airflow, and Vertex AI allow teams to build workflows, track experiment results, manage models, and version datasets. This automation reduces manual work, improves reliability, and accelerates ML development cycles.
Monitoring is one of the most important—and often overlooked—parts of MLOps. Once deployed, models must be monitored for performance, latency, system health, and accuracy drift. Data in production changes constantly, sometimes gradually (known as data drift) or suddenly (known as concept drift). A model that works well today may become inaccurate tomorrow if user behavior shifts, new competitors enter the market, or external factors such as economic changes or seasonality arise. Monitoring tools track prediction distributions, feature fluctuations, error rates, and confidence levels. Alerts notify teams when retraining or recalibration becomes necessary.
Retraining and updating models are essential for keeping performance optimal. In offline retraining, new data is collected periodically and used to retrain the model at scheduled intervals. Online learning or incremental training updates the model continuously as new data comes in. Automation pipelines manage versioning to ensure older and newer models can be compared and rolled back if needed. Model registries like MLflow Model Registry or Amazon SageMaker Registry track multiple versions, metadata, validation metrics, and deployment history. These registries serve as a central hub for approving, promoting, or retiring models.
Security and governance play a major role in MLOps, especially in industries like healthcare, banking, and cybersecurity. Models can unintentionally expose sensitive data or behave unpredictably under adversarial attacks. Secure MLOps practices include encrypted endpoints, API authentication, role-based access control, audit trails, and ensuring training data complies with regulations like GDPR or HIPAA. Bias detection is also part of ethical MLOps—monitoring model predictions to ensure fairness across demographic groups and preventing discriminatory outcomes. Governance frameworks ensure the model remains compliant, safe, and transparent during its entire lifecycle.
Scaling MLOps requires collaboration across multiple teams, not just data scientists. Engineers, DevOps specialists, cloud architects, and product managers all contribute to building a robust ML ecosystem. Cloud platforms such as AWS, Azure, and Google Cloud offer managed MLOps solutions like SageMaker, AzureML, and Vertex AI, reducing complexity and making deployment more accessible. These platforms integrate storage, compute, model training, monitoring, and pipelines in a unified ecosystem. As machine learning applications expand further into personalization, automation, prediction, and optimization, organizations with strong MLOps practices gain a competitive advantage.
Model Deployment and MLOps transform machine learning from a research activity into a scalable production system capable of delivering business value continuously. They empower companies to adapt quickly to new data, maintain accuracy in changing environments, and confidently rely on AI to support critical decisions. As ML adoption grows worldwide, MLOps is rapidly becoming a must-have discipline—ensuring stability, reliability, automation, and long-term performance of machine learning systems.