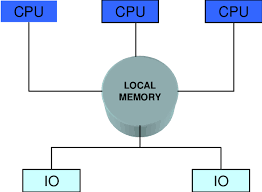
Memory-bound vs CPU-bound optimization is about identifying what limits the performance of a program: the speed of computation or the speed of accessing data. Every system has both CPU processing capability and memory bandwidth. When a program is slow, one of these resources is typically the bottleneck, and optimization must target the correct constraint.
In CPU-bound programs, the processor spends most of its time performing complex calculations such as encryption, data compression, image processing, scientific simulations, or machine learning model inference. The CPU is the resource under pressure, and performance can improve by increasing parallelism, optimizing algorithms, or offloading work to GPUs or other accelerators.
In memory-bound programs, the CPU is waiting for data to arrive from memory or storage. This often occurs in large dataset processing, database workloads, big loops over huge arrays, and applications with poor caching behavior. Optimization focuses on improving memory locality, reducing cache misses, and minimizing data movement rather than compute speed.
Tools like profilers help determine whether code is CPU-bound or memory-bound by analyzing CPU utilization, cache hit ratios, and wait times. If the CPU is highly utilized but performance remains slow, the system may benefit from faster algorithms or multi-threading. If CPU usage is low and threads spend time stalled, the real issue is memory throughput.
For CPU-bound workloads, common optimizations include vectorization, using multi-core parallelism, reducing branching, refining algorithms, and utilizing JIT compiler improvements. Even selecting efficient data structures influences how fast the CPU performs operations on them.
For memory-bound workloads, data layout, caching strategy, and batching become critical. Techniques like loop tiling, minimizing pointer chasing, using contiguous arrays over linked lists, and reducing object overhead enable better exploitation of CPU caches. Databases also rely on indexing and columnar storage to reduce costly disk access.
Modern processors are extremely fast, but memory has not scaled at the same rate — a problem known as the memory wall. Architectural features such as multi-level caches (L1, L2, L3), prefetching, and NUMA optimization are designed to close the gap between compute and data movement, but software must be written to leverage them.
Understanding whether code is memory-bound or CPU-bound guides engineers to apply the right optimization strategy. Optimizing the wrong resource — like adding CPU threads to a memory-limited program — can even make performance worse. Smart developers profile first, then optimize based on data, ensuring speed improvements are real, measurable, and scalable.
In summary, CPU-bound optimization improves computational efficiency, while memory-bound optimization improves data access efficiency. Recognizing the distinction leads to targeted improvements and high-performance systems that fully utilize available hardware potential.
In CPU-bound programs, the processor spends most of its time performing complex calculations such as encryption, data compression, image processing, scientific simulations, or machine learning model inference. The CPU is the resource under pressure, and performance can improve by increasing parallelism, optimizing algorithms, or offloading work to GPUs or other accelerators.
In memory-bound programs, the CPU is waiting for data to arrive from memory or storage. This often occurs in large dataset processing, database workloads, big loops over huge arrays, and applications with poor caching behavior. Optimization focuses on improving memory locality, reducing cache misses, and minimizing data movement rather than compute speed.
Tools like profilers help determine whether code is CPU-bound or memory-bound by analyzing CPU utilization, cache hit ratios, and wait times. If the CPU is highly utilized but performance remains slow, the system may benefit from faster algorithms or multi-threading. If CPU usage is low and threads spend time stalled, the real issue is memory throughput.
For CPU-bound workloads, common optimizations include vectorization, using multi-core parallelism, reducing branching, refining algorithms, and utilizing JIT compiler improvements. Even selecting efficient data structures influences how fast the CPU performs operations on them.
For memory-bound workloads, data layout, caching strategy, and batching become critical. Techniques like loop tiling, minimizing pointer chasing, using contiguous arrays over linked lists, and reducing object overhead enable better exploitation of CPU caches. Databases also rely on indexing and columnar storage to reduce costly disk access.
Modern processors are extremely fast, but memory has not scaled at the same rate — a problem known as the memory wall. Architectural features such as multi-level caches (L1, L2, L3), prefetching, and NUMA optimization are designed to close the gap between compute and data movement, but software must be written to leverage them.
Understanding whether code is memory-bound or CPU-bound guides engineers to apply the right optimization strategy. Optimizing the wrong resource — like adding CPU threads to a memory-limited program — can even make performance worse. Smart developers profile first, then optimize based on data, ensuring speed improvements are real, measurable, and scalable.
In summary, CPU-bound optimization improves computational efficiency, while memory-bound optimization improves data access efficiency. Recognizing the distinction leads to targeted improvements and high-performance systems that fully utilize available hardware potential.