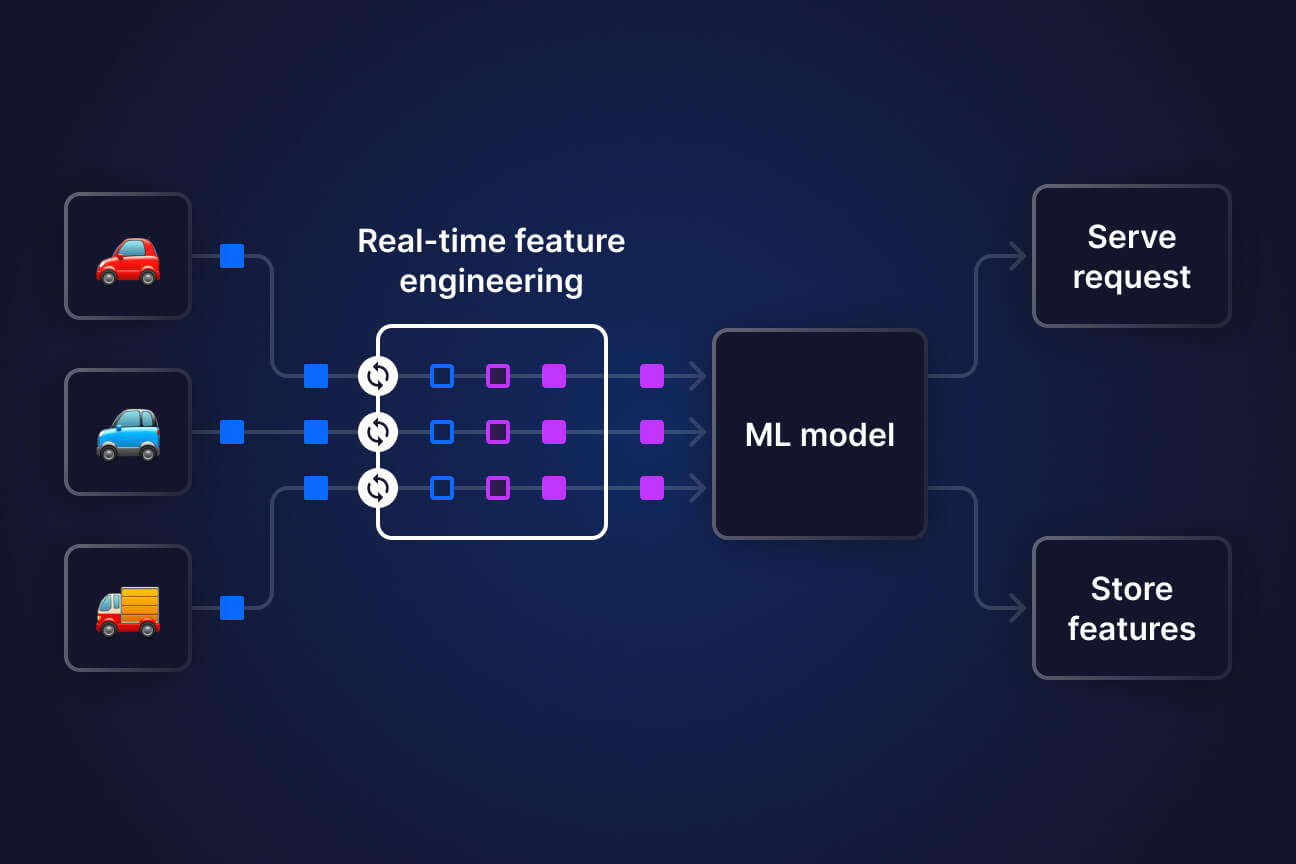
Feature engineering is the process of transforming raw data into meaningful inputs that can be effectively used by analytical and machine learning models. High-quality features play a critical role in determining model accuracy, robustness, and overall performance. Well-engineered features help models capture underlying patterns in data and produce more reliable predictions.
This topic begins with an understanding of data quality dimensions such as accuracy, completeness, consistency, and timeliness. Poor data quality often leads to biased or unreliable results, regardless of how advanced the modeling technique is. By assessing and improving data quality early, learners build a strong foundation for effective analysis.
Learners explore essential data cleaning and transformation techniques used in feature engineering. These include handling missing values, correcting inconsistencies, and managing outliers that can distort model behavior. Normalization and transformation steps help standardize data and make it suitable for downstream processing.
Feature selection methods are introduced to identify the most relevant variables for a given problem. Removing redundant, irrelevant, or noisy features improves model efficiency, reduces overfitting, and simplifies interpretation. Thoughtful feature selection ensures that models focus on the most informative aspects of the data.
Feature scaling and encoding techniques are discussed to prepare data for different types of algorithms. Numerical scaling methods and categorical encoding strategies ensure that features are represented in a way that algorithms can effectively learn from. Proper data representation directly influences model convergence and performance.
Detecting and addressing data bias and class imbalance is an important part of feature engineering. Skewed or imbalanced data can lead to unfair or inaccurate models. By applying balancing techniques and bias detection methods, learners create models that are more equitable and generalizable.
Data drift monitoring is introduced to track how data distributions change over time. As real-world data evolves, previously engineered features may lose relevance or behave differently. Monitoring drift helps maintain model performance and reliability in production environments.
Automation tools and feature engineering pipelines are discussed to scale workflows efficiently. Automated processes ensure consistency, reduce manual effort, and support continuous model improvement. Overall, this topic helps learners build reliable, high-quality datasets that support accurate, trustworthy, and scalable analytics.
This topic begins with an understanding of data quality dimensions such as accuracy, completeness, consistency, and timeliness. Poor data quality often leads to biased or unreliable results, regardless of how advanced the modeling technique is. By assessing and improving data quality early, learners build a strong foundation for effective analysis.
Learners explore essential data cleaning and transformation techniques used in feature engineering. These include handling missing values, correcting inconsistencies, and managing outliers that can distort model behavior. Normalization and transformation steps help standardize data and make it suitable for downstream processing.
Feature selection methods are introduced to identify the most relevant variables for a given problem. Removing redundant, irrelevant, or noisy features improves model efficiency, reduces overfitting, and simplifies interpretation. Thoughtful feature selection ensures that models focus on the most informative aspects of the data.
Feature scaling and encoding techniques are discussed to prepare data for different types of algorithms. Numerical scaling methods and categorical encoding strategies ensure that features are represented in a way that algorithms can effectively learn from. Proper data representation directly influences model convergence and performance.
Detecting and addressing data bias and class imbalance is an important part of feature engineering. Skewed or imbalanced data can lead to unfair or inaccurate models. By applying balancing techniques and bias detection methods, learners create models that are more equitable and generalizable.
Data drift monitoring is introduced to track how data distributions change over time. As real-world data evolves, previously engineered features may lose relevance or behave differently. Monitoring drift helps maintain model performance and reliability in production environments.
Automation tools and feature engineering pipelines are discussed to scale workflows efficiently. Automated processes ensure consistency, reduce manual effort, and support continuous model improvement. Overall, this topic helps learners build reliable, high-quality datasets that support accurate, trustworthy, and scalable analytics.