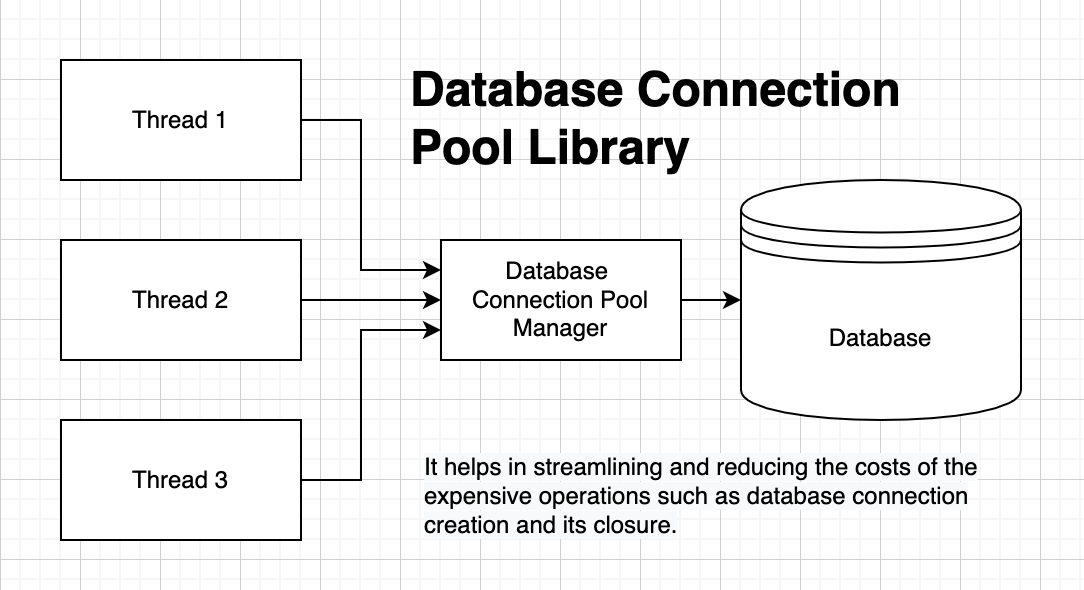
Database Connection Pool Architecture focuses on efficiently managing the limited number of database connections available to an application. Each database connection requires memory, CPU, and network resources, so opening a new connection for every request can be extremely slow and expensive. A connection pool solves this by maintaining a reusable set of active connections that applications can borrow when needed and return when finished.
When an application starts, the connection pool initializes with a predefined number of connections — called the initial pool size. These connections remain open and ready for use, reducing the overhead of repeatedly creating and destroying connections. During peak load, the pool can expand up to a configured maximum size, ensuring the system handles more requests without overwhelming the database.
A connection pool uses intelligent scheduling to manage usage. If all connections are currently in use and the pool has reached its maximum size, incoming requests are queued until a connection becomes available. This maintains stability and prevents the database from crashing due to overload or resource exhaustion.
Connection pools also monitor the health and lifecycle of connections. Idle or stale connections can be closed after a timeout to free resources. If a connection becomes corrupted or unusable, it is safely discarded and replaced with a new one. This keeps the system resilient and prevents database errors from propagating into the application.
To maximize performance, pools use various settings like min idle connections, max lifetime, and acquisition timeout, which allow developers to tune the pool behavior based on traffic patterns. Efficient pooling reduces latency significantly by eliminating connection setup time — especially in high-concurrency environments like financial systems, e-commerce platforms, and SaaS services.
Security is also improved through connection pooling. Since authentication and encryption are handled once at connection creation, sensitive credentials are not repeatedly exposed. Further, access control and auditing can be centralized at the pool layer to enforce strict policies on database usage.
Different programming ecosystems offer robust pooling libraries — such as HikariCP for Java, pgBouncer for PostgreSQL, c3p0, DBCP, and built-in pools in frameworks like Spring Boot and Node.js drivers. Cloud platforms also provide pooling solutions tightly integrated with managed databases.
Connection pooling becomes especially crucial in microservices and serverless architectures. Without pooling, each service instance could create too many transient connections, quickly exhausting database limits. Proper pool configuration ensures scalability, stability, and predictable performance even as traffic fluctuates.
In summary, a well-designed database connection pool architecture minimizes resource overhead, improves speed, enhances reliability, and protects the database from overload. It is a vital component in high-performance systems and one of the most impactful optimizations in backend engineering.
When an application starts, the connection pool initializes with a predefined number of connections — called the initial pool size. These connections remain open and ready for use, reducing the overhead of repeatedly creating and destroying connections. During peak load, the pool can expand up to a configured maximum size, ensuring the system handles more requests without overwhelming the database.
A connection pool uses intelligent scheduling to manage usage. If all connections are currently in use and the pool has reached its maximum size, incoming requests are queued until a connection becomes available. This maintains stability and prevents the database from crashing due to overload or resource exhaustion.
Connection pools also monitor the health and lifecycle of connections. Idle or stale connections can be closed after a timeout to free resources. If a connection becomes corrupted or unusable, it is safely discarded and replaced with a new one. This keeps the system resilient and prevents database errors from propagating into the application.
To maximize performance, pools use various settings like min idle connections, max lifetime, and acquisition timeout, which allow developers to tune the pool behavior based on traffic patterns. Efficient pooling reduces latency significantly by eliminating connection setup time — especially in high-concurrency environments like financial systems, e-commerce platforms, and SaaS services.
Security is also improved through connection pooling. Since authentication and encryption are handled once at connection creation, sensitive credentials are not repeatedly exposed. Further, access control and auditing can be centralized at the pool layer to enforce strict policies on database usage.
Different programming ecosystems offer robust pooling libraries — such as HikariCP for Java, pgBouncer for PostgreSQL, c3p0, DBCP, and built-in pools in frameworks like Spring Boot and Node.js drivers. Cloud platforms also provide pooling solutions tightly integrated with managed databases.
Connection pooling becomes especially crucial in microservices and serverless architectures. Without pooling, each service instance could create too many transient connections, quickly exhausting database limits. Proper pool configuration ensures scalability, stability, and predictable performance even as traffic fluctuates.
In summary, a well-designed database connection pool architecture minimizes resource overhead, improves speed, enhances reliability, and protects the database from overload. It is a vital component in high-performance systems and one of the most impactful optimizations in backend engineering.