In the era of big data and modern analytics, organizations generate massive volumes of information from customer interactions, applications, IoT devices, servers, cloud platforms, and enterprise systems. To transform this raw data into usable insights, businesses rely on Data Pipelines and ETL processes (Extract, Transform, Load). These systems automate the movement, cleaning, transformation, and loading of data from one location to another—typically from operational systems to analytical environments. Without pipelines and ETL, data would remain scattered, inconsistent, and unusable for advanced analytics, reporting, or machine learning. Data pipelines enable continuous data flow, ensuring that decision-makers always have access to accurate, current, and well-structured information.
Data pipelines represent the end-to-end flow of data from the source system to the destination system. They consist of a series of connected processes that extract data, perform transformations, validate quality, and load it into target systems such as data warehouses, data lakes, or business intelligence platforms. Unlike traditional manual data processing, pipelines automate this flow, enabling real-time or scheduled data movement with minimal errors. Pipelines can be batch-based—moving data periodically—or real-time, streaming data instantly as it is generated. The choice depends on business needs: financial systems often need near real-time accuracy, while marketing analysis may rely on nightly batch pipelines.
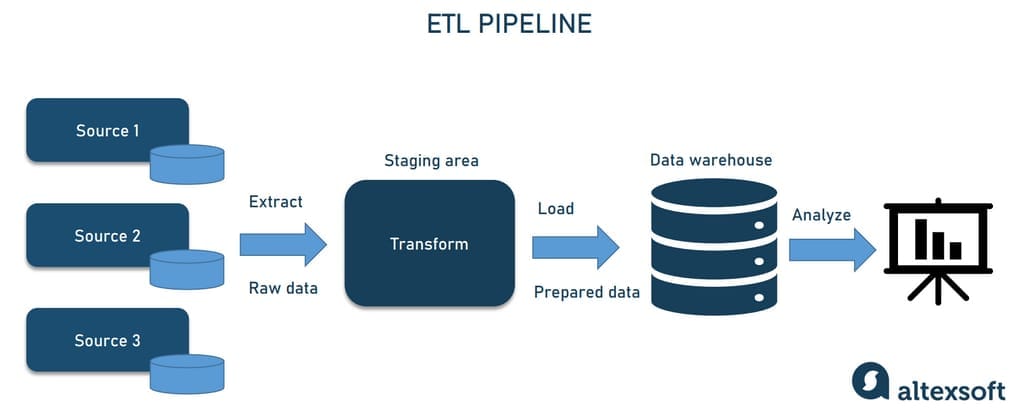
The core of pipeline architecture is ETL (Extract, Transform, Load), a process responsible for making data ready for analysis. The extraction phase involves pulling data from diverse sources such as relational databases, SaaS applications, APIs, sensors, logs, and files. The transformation phase cleans, filters, aggregates, formats, and enriches the data. This stage ensures that data is accurate, consistent, and analytics-ready. Transformations may include removing duplicates, handling missing values, converting units, joining datasets, or applying business logic. The load phase stores the transformed data into a destination such as Snowflake, Google BigQuery, AWS Redshift, or Azure Synapse. ETL ensures that data conforms to the required format and structure for efficient querying and visualization.
As businesses adopt cloud-native architectures, a modern variant called ELT (Extract, Load, Transform) has gained popularity. Unlike ETL, ELT loads raw data into the target system first—typically a powerful cloud data warehouse—and performs transformations inside the warehouse using SQL. With cloud platforms capable of handling massive processing workloads, ELT provides more flexibility, scalability, and speed. It allows analysts to re-transform data anytime, supports large-scale machine learning workflows, and reduces delays seen in traditional ETL. ELT is particularly powerful for organizations using big data tools like Databricks, Snowflake, and BigQuery, which can process petabytes of data efficiently.
Data pipelines also play a crucial role in data quality management, ensuring that data used for decision-making is accurate, reliable, and trustworthy. Poor-quality data leads to faulty insights, financial losses, and flawed business decisions. Pipelines incorporate validation steps such as schema checks, anomaly detection, duplicate detection, and completeness checks. Modern pipeline orchestration tools like Apache Airflow, AWS Glue, Google Dataflow, and Azure Data Factory have built-in monitoring capabilities to detect failures, delays, or incorrect transformations. This visibility helps data engineers quickly address issues and maintain smooth pipeline operations.
Another important aspect of pipelines is orchestration and automation. Data pipelines often consist of multiple interconnected tasks with dependencies—one process may rely on the output of another. Orchestration tools manage these sequences, scheduling tasks, triggering workflows, and monitoring execution. Airflow’s Directed Acyclic Graphs (DAGs) are a popular method to visualize and manage workflow dependencies. Automation reduces manual intervention, improves reliability, and allows organizations to operate at scale. With orchestration, teams ensure that data is delivered on time, every time, regardless of complexity.
Real-time data pipelines, powered by technologies such as Apache Kafka, Apache Flink, AWS Kinesis, and Google Pub/Sub, enable streaming data processing. These systems continuously ingest and process data as it arrives, making them ideal for applications such as fraud detection, IoT monitoring, live dashboards, and recommendation engines. Stream processing frameworks analyze data in motion, enabling immediate insights and automated responses. Real-time pipelines are increasingly essential in modern digital ecosystems where instant intelligence drives competitive advantage.
Security and governance are essential considerations in designing data pipelines. Sensitive data—financial transactions, personal information, medical records—must be encrypted during extraction, transit, and storage. Access control mechanisms ensure that only authorized individuals and services can interact with pipeline components. Data lineage tracking—understanding where data originates, how it is transformed, and where it flows—provides transparency for audits and regulatory compliance. Governance ensures that pipelines remain secure, compliant, and ethical, especially under global regulations like GDPR, HIPAA, or India’s DPDP Act.
In conclusion, Data Pipelines and ETL form the backbone of modern data ecosystems, ensuring that raw data is transformed into meaningful insights in an automated, scalable, and reliable manner. As businesses increasingly rely on analytics, AI, and real-time decision-making, efficient pipeline architecture becomes mission-critical. Organizations that invest in strong data engineering foundations gain faster insights, higher data accuracy, and the ability to scale their analytics initiatives. Whether through batch ETL, cloud-native ELT, or real-time streaming pipelines, the goal remains the same: to deliver clean, timely, and actionable data that empowers smarter decisions and drives business success.
Data pipelines represent the end-to-end flow of data from the source system to the destination system. They consist of a series of connected processes that extract data, perform transformations, validate quality, and load it into target systems such as data warehouses, data lakes, or business intelligence platforms. Unlike traditional manual data processing, pipelines automate this flow, enabling real-time or scheduled data movement with minimal errors. Pipelines can be batch-based—moving data periodically—or real-time, streaming data instantly as it is generated. The choice depends on business needs: financial systems often need near real-time accuracy, while marketing analysis may rely on nightly batch pipelines.
The core of pipeline architecture is ETL (Extract, Transform, Load), a process responsible for making data ready for analysis. The extraction phase involves pulling data from diverse sources such as relational databases, SaaS applications, APIs, sensors, logs, and files. The transformation phase cleans, filters, aggregates, formats, and enriches the data. This stage ensures that data is accurate, consistent, and analytics-ready. Transformations may include removing duplicates, handling missing values, converting units, joining datasets, or applying business logic. The load phase stores the transformed data into a destination such as Snowflake, Google BigQuery, AWS Redshift, or Azure Synapse. ETL ensures that data conforms to the required format and structure for efficient querying and visualization.
As businesses adopt cloud-native architectures, a modern variant called ELT (Extract, Load, Transform) has gained popularity. Unlike ETL, ELT loads raw data into the target system first—typically a powerful cloud data warehouse—and performs transformations inside the warehouse using SQL. With cloud platforms capable of handling massive processing workloads, ELT provides more flexibility, scalability, and speed. It allows analysts to re-transform data anytime, supports large-scale machine learning workflows, and reduces delays seen in traditional ETL. ELT is particularly powerful for organizations using big data tools like Databricks, Snowflake, and BigQuery, which can process petabytes of data efficiently.
Data pipelines also play a crucial role in data quality management, ensuring that data used for decision-making is accurate, reliable, and trustworthy. Poor-quality data leads to faulty insights, financial losses, and flawed business decisions. Pipelines incorporate validation steps such as schema checks, anomaly detection, duplicate detection, and completeness checks. Modern pipeline orchestration tools like Apache Airflow, AWS Glue, Google Dataflow, and Azure Data Factory have built-in monitoring capabilities to detect failures, delays, or incorrect transformations. This visibility helps data engineers quickly address issues and maintain smooth pipeline operations.
Another important aspect of pipelines is orchestration and automation. Data pipelines often consist of multiple interconnected tasks with dependencies—one process may rely on the output of another. Orchestration tools manage these sequences, scheduling tasks, triggering workflows, and monitoring execution. Airflow’s Directed Acyclic Graphs (DAGs) are a popular method to visualize and manage workflow dependencies. Automation reduces manual intervention, improves reliability, and allows organizations to operate at scale. With orchestration, teams ensure that data is delivered on time, every time, regardless of complexity.
Real-time data pipelines, powered by technologies such as Apache Kafka, Apache Flink, AWS Kinesis, and Google Pub/Sub, enable streaming data processing. These systems continuously ingest and process data as it arrives, making them ideal for applications such as fraud detection, IoT monitoring, live dashboards, and recommendation engines. Stream processing frameworks analyze data in motion, enabling immediate insights and automated responses. Real-time pipelines are increasingly essential in modern digital ecosystems where instant intelligence drives competitive advantage.
Security and governance are essential considerations in designing data pipelines. Sensitive data—financial transactions, personal information, medical records—must be encrypted during extraction, transit, and storage. Access control mechanisms ensure that only authorized individuals and services can interact with pipeline components. Data lineage tracking—understanding where data originates, how it is transformed, and where it flows—provides transparency for audits and regulatory compliance. Governance ensures that pipelines remain secure, compliant, and ethical, especially under global regulations like GDPR, HIPAA, or India’s DPDP Act.
In conclusion, Data Pipelines and ETL form the backbone of modern data ecosystems, ensuring that raw data is transformed into meaningful insights in an automated, scalable, and reliable manner. As businesses increasingly rely on analytics, AI, and real-time decision-making, efficient pipeline architecture becomes mission-critical. Organizations that invest in strong data engineering foundations gain faster insights, higher data accuracy, and the ability to scale their analytics initiatives. Whether through batch ETL, cloud-native ELT, or real-time streaming pipelines, the goal remains the same: to deliver clean, timely, and actionable data that empowers smarter decisions and drives business success.