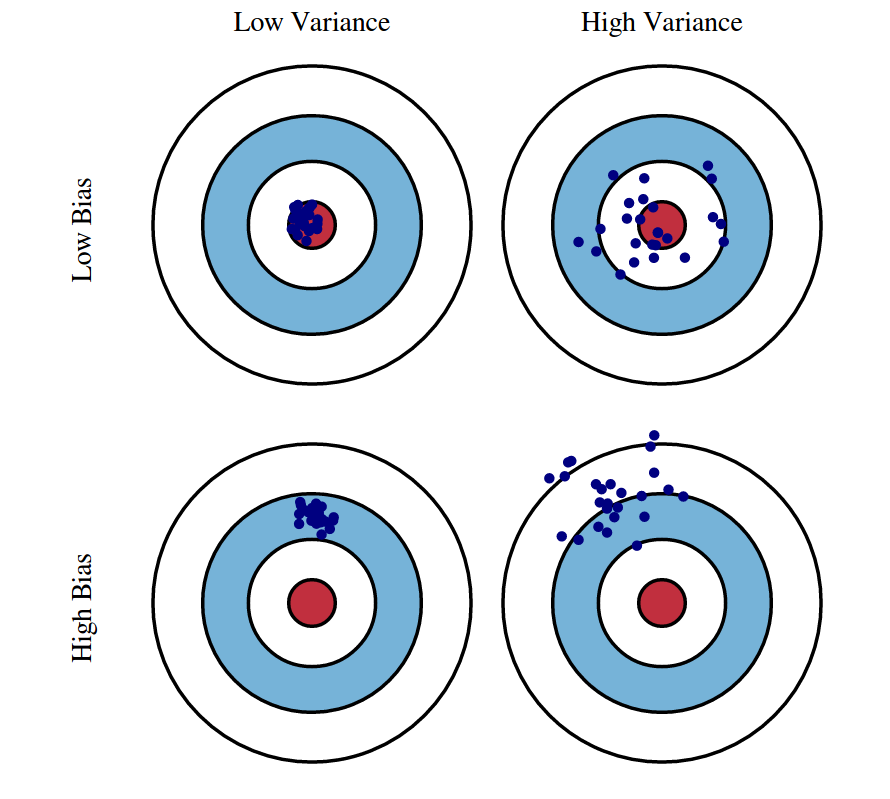
The bias–variance tradeoff is a fundamental concept in machine learning that explains the balance between two main sources of model error: bias and variance. Bias represents the error introduced when a model is too simple and cannot capture the underlying patterns in the data. Variance represents the error that occurs when a model is too sensitive to small fluctuations in the training data. Understanding this balance is critical because it determines how well a model can generalize to new, unseen data.
Bias occurs when a model makes strong assumptions about the data, leading to underfitting. Underfitted models fail to capture important relationships in the dataset, producing predictions that are consistently inaccurate. For example, using a simple linear regression for a highly nonlinear dataset introduces high bias. Such models exhibit low complexity, fast training, and stability, but their performance is limited because they oversimplify the problem.
Variance, on the other hand, arises when a model learns too much from the training data, including noise and random fluctuations. This leads to overfitting, where the model performs extremely well on training examples but poorly on test data. High-variance models adapt too closely to specific sample patterns and fail to generalize. Deep trees, overly complex neural networks, or models trained on insufficient data often exhibit high variance because they memorize rather than learn.
The tradeoff refers to finding the right balance between bias and variance to minimize total model error. Reducing bias usually increases variance, and reducing variance typically increases bias. The goal is not to eliminate one or the other, but to achieve an optimal combination where the model is neither too simple nor too complex. This balance ensures the model performs well both during training and when making real-world predictions.
Model complexity plays a crucial role in this tradeoff. As complexity increases, bias decreases because the model can capture more intricate relationships. However, variance increases because the model becomes more sensitive to data noise. Graphically, this is seen as a U-shaped curve for total error, with the optimal point occurring where bias and variance contribute minimally to the overall loss. Selecting the right level of complexity is essential for effective machine learning.
Regularization techniques help manage the bias–variance tradeoff. Methods such as L1 and L2 regularization, dropout in neural networks, and pruning in decision trees reduce variance by controlling complexity. Regularization discourages the model from fitting noise and encourages simpler, smoother patterns. While it slightly increases bias, it improves generalization by preventing overfitting. The key is tuning regularization strength to achieve the best balance.
Data quality and quantity also influence this tradeoff. More training data generally reduces variance by providing the model with diverse examples, making it harder to memorize noise. Similarly, feature engineering enhances the ability of a model to learn important relationships with lower variance and lower bias. Good dataset design—cleaning, augmentation, and balanced sampling—directly improves the bias–variance balance.
Cross-validation is a powerful tool for evaluating the bias–variance tradeoff. By testing the model’s performance on different subsets of the dataset, it becomes easier to detect overfitting or underfitting patterns. Cross-validation ensures that the chosen model complexity works consistently across varying samples. This method helps teams tune hyperparameters effectively and avoid models that are prone to high bias or high variance.
Ultimately, the bias–variance tradeoff is about achieving strong generalization performance. Machine learning models must learn from training data without becoming overly dependent on it. Designers aim for a model that is flexible enough to capture real patterns but robust enough to ignore noise. Mastering this tradeoff allows practitioners to develop reliable, accurate, and scalable ML systems that perform well in real-world scenarios, not just training environments.
Bias occurs when a model makes strong assumptions about the data, leading to underfitting. Underfitted models fail to capture important relationships in the dataset, producing predictions that are consistently inaccurate. For example, using a simple linear regression for a highly nonlinear dataset introduces high bias. Such models exhibit low complexity, fast training, and stability, but their performance is limited because they oversimplify the problem.
Variance, on the other hand, arises when a model learns too much from the training data, including noise and random fluctuations. This leads to overfitting, where the model performs extremely well on training examples but poorly on test data. High-variance models adapt too closely to specific sample patterns and fail to generalize. Deep trees, overly complex neural networks, or models trained on insufficient data often exhibit high variance because they memorize rather than learn.
The tradeoff refers to finding the right balance between bias and variance to minimize total model error. Reducing bias usually increases variance, and reducing variance typically increases bias. The goal is not to eliminate one or the other, but to achieve an optimal combination where the model is neither too simple nor too complex. This balance ensures the model performs well both during training and when making real-world predictions.
Model complexity plays a crucial role in this tradeoff. As complexity increases, bias decreases because the model can capture more intricate relationships. However, variance increases because the model becomes more sensitive to data noise. Graphically, this is seen as a U-shaped curve for total error, with the optimal point occurring where bias and variance contribute minimally to the overall loss. Selecting the right level of complexity is essential for effective machine learning.
Regularization techniques help manage the bias–variance tradeoff. Methods such as L1 and L2 regularization, dropout in neural networks, and pruning in decision trees reduce variance by controlling complexity. Regularization discourages the model from fitting noise and encourages simpler, smoother patterns. While it slightly increases bias, it improves generalization by preventing overfitting. The key is tuning regularization strength to achieve the best balance.
Data quality and quantity also influence this tradeoff. More training data generally reduces variance by providing the model with diverse examples, making it harder to memorize noise. Similarly, feature engineering enhances the ability of a model to learn important relationships with lower variance and lower bias. Good dataset design—cleaning, augmentation, and balanced sampling—directly improves the bias–variance balance.
Cross-validation is a powerful tool for evaluating the bias–variance tradeoff. By testing the model’s performance on different subsets of the dataset, it becomes easier to detect overfitting or underfitting patterns. Cross-validation ensures that the chosen model complexity works consistently across varying samples. This method helps teams tune hyperparameters effectively and avoid models that are prone to high bias or high variance.
Ultimately, the bias–variance tradeoff is about achieving strong generalization performance. Machine learning models must learn from training data without becoming overly dependent on it. Designers aim for a model that is flexible enough to capture real patterns but robust enough to ignore noise. Mastering this tradeoff allows practitioners to develop reliable, accurate, and scalable ML systems that perform well in real-world scenarios, not just training environments.