Autonomous Cloud Operations represent a major shift in how modern cloud environments are managed, monitored, and maintained. Traditional cloud operations rely on large teams of engineers to handle provisioning, monitoring, scaling, patching, and troubleshooting. However, with applications growing more distributed, dynamic, and complex, manual operations have become time-consuming and prone to human error. Autonomous Cloud Operations aim to eliminate these challenges by creating cloud environments that can independently monitor health, detect anomalies, predict incidents, and automatically resolve issues — all without human intervention. This evolution is driven by smart automation, policy-based orchestration, and real-time data analysis, transforming the cloud from a static environment into a self-sustaining operational ecosystem.
Autonomous Cloud Operations are built on several key principles that allow them to function with minimal human involvement. The first principle is continuous monitoring, where the cloud continuously collects logs, metrics, traces, and events from every component. The second principle is automated decision logic, which uses rule-based engines and anomaly detection models to identify when something is going wrong. Third is self-healing, where the system takes corrective actions like restarting services, reallocating resources, or triggering failovers. Fourth is predictive optimization, where the cloud forecasts future resource needs and auto-scales accordingly. Finally, autonomous operations use closed-loop governance, meaning every action taken feeds intelligence back into the monitoring system. These capabilities allow cloud systems to function like intelligent organisms — observing, learning, and adapting continuously.
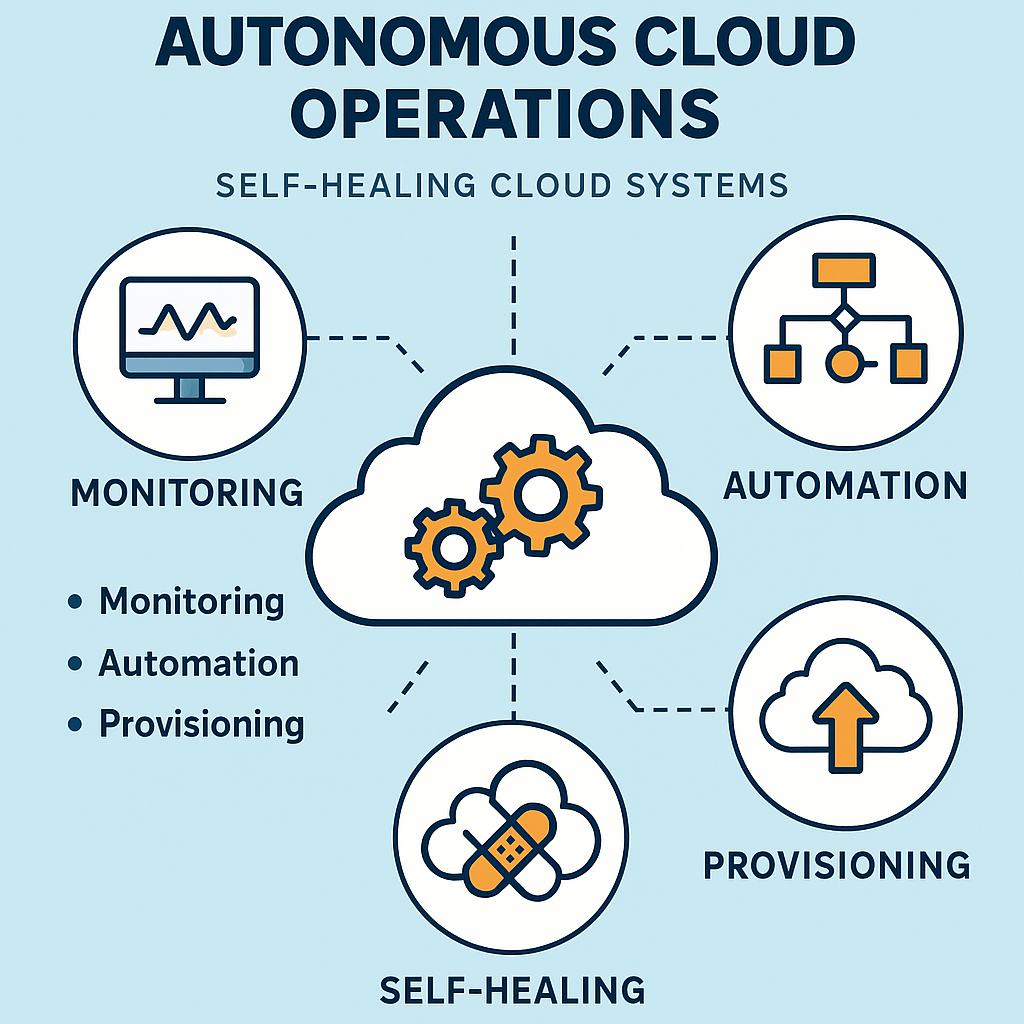
An autonomous cloud system typically consists of several tightly integrated layers: the monitoring layer, analytics layer, automation layer, and orchestration layer. The monitoring layer gathers performance data from servers, containers, databases, and network components. The analytics layer processes this information using AI-driven pattern recognition, rules, and historical trends. The automation layer holds scripts, playbooks, and predefined workflows to perform corrective actions such as clearing memory leaks, rebalancing workloads, or creating replacement compute nodes. The orchestration layer ensures all actions follow business policies and compliance rules. Some enterprises also add a governance layer to track actions, provide audit logs, and maintain transparency. Together, these layers allow the cloud to not just react to problems but anticipate and prevent them, ensuring uninterrupted service delivery.
Autonomous Cloud Operations include a set of transformative features that drastically improve reliability and efficiency. One of the most impactful is self-healing, where systems automatically remedy failures — restarting a crashed container, shifting traffic from a failing node, or rolling back a faulty deployment. Another key feature is AI-driven auto-scaling, which expands or reduces compute capacity based on real-time demand. Intelligent workflow automation ensures that when events occur, the correct operational sequence runs instantly, such as isolating a compromised VM or triggering backup systems. Additionally, automated patching and updates keep infrastructure secure without downtime. Alert noise is also dramatically reduced because the system filters out irrelevant alerts and only escalates meaningful issues to humans when necessary.
Adopting Autonomous Cloud Operations brings enormous business benefits. First, organizations experience significant cost savings because the cloud optimizes resources based on actual demand instead of static provisioning. Second, uptime improves through instant self-healing and proactive failure prevention, helping companies achieve near-zero downtime. Third, engineering teams become more productive because they no longer spend hours resolving repetitive issues or handling routine maintenance. Instead, they focus on higher-value work like architecture improvements. Autonomous operations also enhance security since vulnerabilities are detected and resolved faster. Finally, customers benefit from consistent performance, reduced latency, and more stable digital experiences. For companies managing global-scale cloud environments, autonomy becomes not just a convenience but a necessity.
Several global organizations have already adopted autonomous cloud approaches. Google Cloud’s operations suite uses AI and automation for predictive scaling and anomaly detection. Amazon Web Services uses automation for auto-remediation in services like EC2, RDS, and Lambda. Microsoft Azure uses policy-driven governance and self-healing capabilities to maintain compliance and reliability across large-scale workloads. Netflix is known for its Chaos Engineering framework, which introduces simulated failures so the system can learn how to recover autonomously. Even sectors like banking, healthcare, and telecom now rely on autonomous processes to maintain uptime for mission-critical applications. These real-world implementations illustrate the power of autonomous cloud operations to transform modern IT environments.
Despite its advantages, autonomous cloud operations come with challenges. Building a completely self-healing system requires complex architecture, robust monitoring, and careful policy definitions. Organizations also struggle with the trust factor — allowing a system to take critical decisions autonomously can feel risky. Another challenge is the automation gap, where not all tasks are fully automatable today. Some failures involve business logic, compliance rules, or human judgment that AI cannot replicate. Data quality issues can also hinder accurate predictions. Integrating automation tools across hybrid or multi-cloud environments adds additional complexity. To overcome these barriers, organizations must adopt gradual autonomy, establish strong governance, and maintain human-in-the-loop oversight for high-risk events.
The future of cloud operations is heading toward complete autonomy. Cloud platforms will evolve into highly intelligent environments capable of learning operational patterns, predicting failures with near-perfect accuracy, and resolving issues before they cause disruptions. Multi-cloud autonomy will become standard, where systems optimize workloads across providers based on cost, performance, and compliance. Edge-to-cloud integration will be fully automated, allowing IoT and AI workloads to run seamlessly across distributed ecosystems. Generative AI will play a major role by automatically generating scripts, workflows, and infrastructure templates. In the coming years, IT operations will transform from a manually managed discipline into a fully automated, intelligence-driven digital nervous system.
Autonomous Cloud Operations are built on several key principles that allow them to function with minimal human involvement. The first principle is continuous monitoring, where the cloud continuously collects logs, metrics, traces, and events from every component. The second principle is automated decision logic, which uses rule-based engines and anomaly detection models to identify when something is going wrong. Third is self-healing, where the system takes corrective actions like restarting services, reallocating resources, or triggering failovers. Fourth is predictive optimization, where the cloud forecasts future resource needs and auto-scales accordingly. Finally, autonomous operations use closed-loop governance, meaning every action taken feeds intelligence back into the monitoring system. These capabilities allow cloud systems to function like intelligent organisms — observing, learning, and adapting continuously.
An autonomous cloud system typically consists of several tightly integrated layers: the monitoring layer, analytics layer, automation layer, and orchestration layer. The monitoring layer gathers performance data from servers, containers, databases, and network components. The analytics layer processes this information using AI-driven pattern recognition, rules, and historical trends. The automation layer holds scripts, playbooks, and predefined workflows to perform corrective actions such as clearing memory leaks, rebalancing workloads, or creating replacement compute nodes. The orchestration layer ensures all actions follow business policies and compliance rules. Some enterprises also add a governance layer to track actions, provide audit logs, and maintain transparency. Together, these layers allow the cloud to not just react to problems but anticipate and prevent them, ensuring uninterrupted service delivery.
Autonomous Cloud Operations include a set of transformative features that drastically improve reliability and efficiency. One of the most impactful is self-healing, where systems automatically remedy failures — restarting a crashed container, shifting traffic from a failing node, or rolling back a faulty deployment. Another key feature is AI-driven auto-scaling, which expands or reduces compute capacity based on real-time demand. Intelligent workflow automation ensures that when events occur, the correct operational sequence runs instantly, such as isolating a compromised VM or triggering backup systems. Additionally, automated patching and updates keep infrastructure secure without downtime. Alert noise is also dramatically reduced because the system filters out irrelevant alerts and only escalates meaningful issues to humans when necessary.
Adopting Autonomous Cloud Operations brings enormous business benefits. First, organizations experience significant cost savings because the cloud optimizes resources based on actual demand instead of static provisioning. Second, uptime improves through instant self-healing and proactive failure prevention, helping companies achieve near-zero downtime. Third, engineering teams become more productive because they no longer spend hours resolving repetitive issues or handling routine maintenance. Instead, they focus on higher-value work like architecture improvements. Autonomous operations also enhance security since vulnerabilities are detected and resolved faster. Finally, customers benefit from consistent performance, reduced latency, and more stable digital experiences. For companies managing global-scale cloud environments, autonomy becomes not just a convenience but a necessity.
Several global organizations have already adopted autonomous cloud approaches. Google Cloud’s operations suite uses AI and automation for predictive scaling and anomaly detection. Amazon Web Services uses automation for auto-remediation in services like EC2, RDS, and Lambda. Microsoft Azure uses policy-driven governance and self-healing capabilities to maintain compliance and reliability across large-scale workloads. Netflix is known for its Chaos Engineering framework, which introduces simulated failures so the system can learn how to recover autonomously. Even sectors like banking, healthcare, and telecom now rely on autonomous processes to maintain uptime for mission-critical applications. These real-world implementations illustrate the power of autonomous cloud operations to transform modern IT environments.
Despite its advantages, autonomous cloud operations come with challenges. Building a completely self-healing system requires complex architecture, robust monitoring, and careful policy definitions. Organizations also struggle with the trust factor — allowing a system to take critical decisions autonomously can feel risky. Another challenge is the automation gap, where not all tasks are fully automatable today. Some failures involve business logic, compliance rules, or human judgment that AI cannot replicate. Data quality issues can also hinder accurate predictions. Integrating automation tools across hybrid or multi-cloud environments adds additional complexity. To overcome these barriers, organizations must adopt gradual autonomy, establish strong governance, and maintain human-in-the-loop oversight for high-risk events.
The future of cloud operations is heading toward complete autonomy. Cloud platforms will evolve into highly intelligent environments capable of learning operational patterns, predicting failures with near-perfect accuracy, and resolving issues before they cause disruptions. Multi-cloud autonomy will become standard, where systems optimize workloads across providers based on cost, performance, and compliance. Edge-to-cloud integration will be fully automated, allowing IoT and AI workloads to run seamlessly across distributed ecosystems. Generative AI will play a major role by automatically generating scripts, workflows, and infrastructure templates. In the coming years, IT operations will transform from a manually managed discipline into a fully automated, intelligence-driven digital nervous system.