A/B Testing and Experiment Design are essential techniques used in data science, product development, marketing, and UX optimization to make decisions based on evidence rather than intuition. At their core, these methods help organizations determine whether a change—such as a new feature, layout, or strategy—creates a meaningful improvement. Instead of relying solely on opinions, A/B testing uses structured experiments to compare two or more variations and identify the version that performs better. This scientific approach significantly reduces risk, improves user experience, and drives continuous product improvement.
A/B testing begins by defining a clear objective. Whether the goal is to increase website conversions, improve app engagement, reduce bounce rate, or enhance user satisfaction, a well-defined hypothesis guides the entire experiment. A strong hypothesis states what change is being tested and predicts its expected impact. For example, “Changing the call-to-action button color to green will increase click-through rates.” A clearly defined goal ensures the experiment remains focused and measurable. It also helps avoid testing irrelevant variations that do not contribute to business impact.
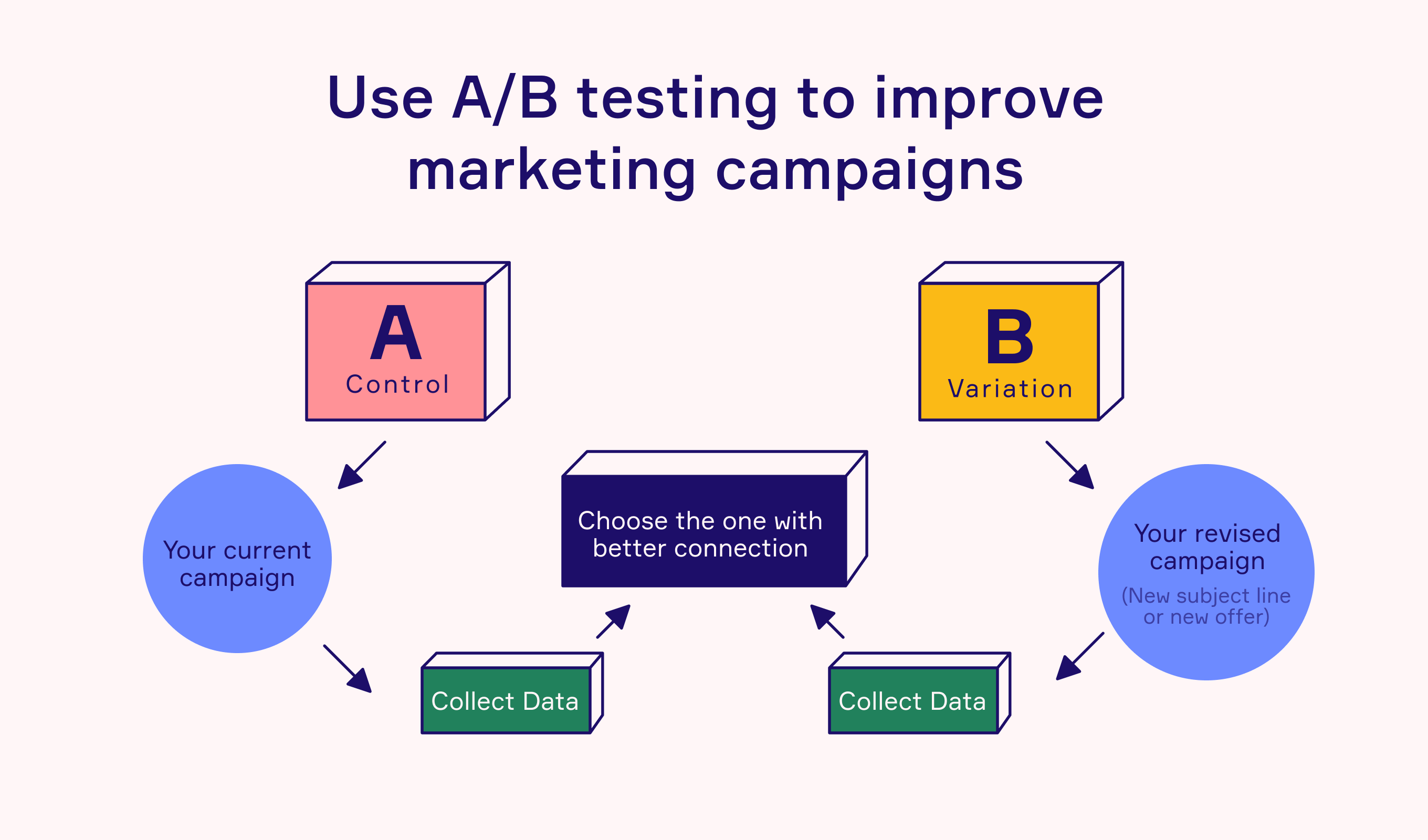
Experiment design requires identifying and isolating a single variable to test. The simplest form of testing involves two versions: Version A (control) and Version B (treatment). The control represents the current version, while the treatment introduces a change. Test participants are randomly split into these groups to avoid bias. Randomization ensures that differences in behavior arise from the version being tested rather than demographic or behavioral differences among the users. Proper randomization and sample distribution are foundations of trustworthy A/B testing.
A crucial component of experiment design is determining the appropriate sample size and test duration. If the sample size is too small, results may be unreliable, prone to randomness, and lack statistical significance. If the sample size is too large or the test period is too long, organizations may waste time and resources. Statistical power analysis helps estimate how many users are needed to detect meaningful differences. Additionally, experiments should run long enough to capture variations in daily or weekly traffic patterns but not so long that external factors influence the results. Balancing duration and sample size leads to more accurate conclusions.
Statistical significance plays a central role in interpreting A/B test results. Metrics such as conversion rate, click-through rate, engagement, or revenue per user are compared across groups. Hypothesis testing—often through t-tests, chi-square tests, or Bayesian analysis—determines whether observed differences are due to chance or represent a real effect. A commonly used significance level is 0.05, meaning the probability of wrongly concluding that the change worked is less than 5%. Alongside statistical significance, practical significance matters as well. A small improvement may be statistically significant but not large enough to justify implementing the change.
Experiment Design extends beyond simple A/B comparisons. More complex scenarios include multivariate testing, which tests multiple elements simultaneously, and multi-armed bandit experiments, which dynamically allocate more traffic to the better-performing versions while the test is running. These methods allow organizations to test more variations efficiently and reduce opportunity costs. However, they require more advanced analytics and careful interpretation. The chosen experiment type depends on the complexity of the change, traffic volume, and business objectives.
A/B testing is used widely across industries. In e-commerce, businesses test product page layouts, pricing displays, and promotional banners. In mobile apps, developers test onboarding flows, navigation patterns, and feature placements. Marketing teams use A/B testing to compare email subject lines, ad creatives, and landing pages. UX designers test typography, colors, and micro-interactions to enhance the user experience. These experiments create a culture of continuous optimization, where decisions are constantly refined based on user behavior and generated data.
Successful experimentation requires avoiding common pitfalls such as peeking (checking results too early), running multiple tests on overlapping audiences, ignoring external events, or failing to control for confounding variables. Peeking can distort results by prematurely ending the experiment when temporary fluctuations appear favorable. Overlapping experiments may pollute data because one test can influence another. Good experiment design ensures that each test is isolated, unbiased, and aligns with long-term business goals. Monitoring experiment health throughout the test helps maintain accuracy.
A/B Testing and Experiment Design empower organizations to make data-driven decisions, reduce risk, and continuously improve products. By combining strong hypotheses, controlled variables, statistical rigor, and thoughtful interpretation, organizations uncover what truly resonates with users. This scientific approach enhances performance, user satisfaction, and business growth. As digital ecosystems grow more complex, A/B testing remains a powerful tool for validating ideas, optimizing experiences, and driving innovation with confidence.
A/B testing begins by defining a clear objective. Whether the goal is to increase website conversions, improve app engagement, reduce bounce rate, or enhance user satisfaction, a well-defined hypothesis guides the entire experiment. A strong hypothesis states what change is being tested and predicts its expected impact. For example, “Changing the call-to-action button color to green will increase click-through rates.” A clearly defined goal ensures the experiment remains focused and measurable. It also helps avoid testing irrelevant variations that do not contribute to business impact.
Experiment design requires identifying and isolating a single variable to test. The simplest form of testing involves two versions: Version A (control) and Version B (treatment). The control represents the current version, while the treatment introduces a change. Test participants are randomly split into these groups to avoid bias. Randomization ensures that differences in behavior arise from the version being tested rather than demographic or behavioral differences among the users. Proper randomization and sample distribution are foundations of trustworthy A/B testing.
A crucial component of experiment design is determining the appropriate sample size and test duration. If the sample size is too small, results may be unreliable, prone to randomness, and lack statistical significance. If the sample size is too large or the test period is too long, organizations may waste time and resources. Statistical power analysis helps estimate how many users are needed to detect meaningful differences. Additionally, experiments should run long enough to capture variations in daily or weekly traffic patterns but not so long that external factors influence the results. Balancing duration and sample size leads to more accurate conclusions.
Statistical significance plays a central role in interpreting A/B test results. Metrics such as conversion rate, click-through rate, engagement, or revenue per user are compared across groups. Hypothesis testing—often through t-tests, chi-square tests, or Bayesian analysis—determines whether observed differences are due to chance or represent a real effect. A commonly used significance level is 0.05, meaning the probability of wrongly concluding that the change worked is less than 5%. Alongside statistical significance, practical significance matters as well. A small improvement may be statistically significant but not large enough to justify implementing the change.
Experiment Design extends beyond simple A/B comparisons. More complex scenarios include multivariate testing, which tests multiple elements simultaneously, and multi-armed bandit experiments, which dynamically allocate more traffic to the better-performing versions while the test is running. These methods allow organizations to test more variations efficiently and reduce opportunity costs. However, they require more advanced analytics and careful interpretation. The chosen experiment type depends on the complexity of the change, traffic volume, and business objectives.
A/B testing is used widely across industries. In e-commerce, businesses test product page layouts, pricing displays, and promotional banners. In mobile apps, developers test onboarding flows, navigation patterns, and feature placements. Marketing teams use A/B testing to compare email subject lines, ad creatives, and landing pages. UX designers test typography, colors, and micro-interactions to enhance the user experience. These experiments create a culture of continuous optimization, where decisions are constantly refined based on user behavior and generated data.
Successful experimentation requires avoiding common pitfalls such as peeking (checking results too early), running multiple tests on overlapping audiences, ignoring external events, or failing to control for confounding variables. Peeking can distort results by prematurely ending the experiment when temporary fluctuations appear favorable. Overlapping experiments may pollute data because one test can influence another. Good experiment design ensures that each test is isolated, unbiased, and aligns with long-term business goals. Monitoring experiment health throughout the test helps maintain accuracy.
A/B Testing and Experiment Design empower organizations to make data-driven decisions, reduce risk, and continuously improve products. By combining strong hypotheses, controlled variables, statistical rigor, and thoughtful interpretation, organizations uncover what truly resonates with users. This scientific approach enhances performance, user satisfaction, and business growth. As digital ecosystems grow more complex, A/B testing remains a powerful tool for validating ideas, optimizing experiences, and driving innovation with confidence.